- Partitionnement de données
-
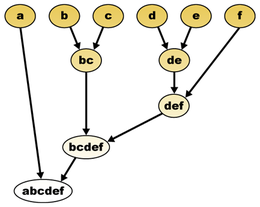 Exemple de clustering hiérarchique
Exemple de clustering hiérarchique
Le partitionnement de données (data clustering en anglais) est une des méthodes Statistiques d'analyse des données. Elle vise à diviser un ensemble de données en différents « paquets » homogènes, en ce sens que les données de chaque sous-ensemble partagent des caractéristiques communes, qui correspondent le plus souvent à des critères de proximité (similarité informatique) que l'on définit en introduisant des mesures et classes de distance entre objets.
Pour obtenir un bon partitionnement, il convient d'à la fois :
- minimiser l'inertie intra-classe pour obtenir des grappes (cluster en anglais) les plus homogènes possibles.
- maximiser l'inertie inter-classe afin d'obtenir des sous-ensembles bien différenciés.
Sommaire
Vocabulaire
La communauté scientifique francophone utilise différents termes pour désigner cette technique.
Le mot anglais clustering est communément employé. On parle également souvent de méthodes de regroupement. on distingue souvent les méthodes « hiérarchiques » et « de partition »Intérêt et applications
Le partitionnement de données est une méthode de classification non supervisée (différente de la classification supervisée où les données d'apprentissage sont déjà étiquetées), et donc parfois dénommée comme telle.
Applications : on en distingue généralement trois sortes[1]
- la segmentation d'une base de données ; elle peut servir à discrétiser une base de données.
La segmentation peut aussi permettre de condenser ou compresser les données d'une base de données spatiales (c'est-à-dire réduire la taille des paquets de données à traiter, dans l'ensemble de données considéré) ; par exemple, dans une image aérienne ou satellitale un SIG peut traiter différemment les forêts, champs, prairies, routes, zones humides, etc. ici considérés comme des sous-espaces homogènes. Un traitement plus fin pouvant ensuite être appliqué à des sous-ensemble de ces classes (ex forêt de feuillus, de résineux, artificielles, naturelles, etc.)
OLAP est une méthode qui facilite l'indexation de telles bases. - la classification (en sous-groupes, sous-populations au sein de la base de donnée), par exemple d'une base de données clients, pour la gestion de la relation client
- l'extraction de connaissances, qui se fait généralement sans objectif a priori (facteur de sérendipité, utile pour la génération d'hypothèse ou modélisation prédictive), pour faire émerger des sous-ensembles et sous-concepts éventuellement impossibles à naturellement distinguer.
Algorithmes
Il existe de multiples méthodes de partitionnement des données, parmi lesquelles :
- La méthode des nuées dynamiques
- Le regroupement hiérarchique
- L'algorithme EM
- L'analyse en composantes principales
Logiciels associés
Voir aussi
Articles connexes
- Intelligence artificielle
- Similarité (informatique)
- Matrice de confusion
- Classification supervisée
- Classification non-supervisée
- Discrétisation
- Bases de données relationnelles
- Informatique décisionnelle
- Modélisation prédictive
- Apprentissage non-supervisé
- Classification double
Liens externes
Bibliographie
- Anil K. Jain, M. N. Murty, P.J. Flynn, Data Clustering: a Review, Journal ACM Computing Surveys, Volume 31 Issue 3, Sept. 1999.
Notes et références
- Berkhin, 2002
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques Portail de l'informatique théorique
Portail de l'informatique théorique
Wikimedia Foundation. 2010.