- PLRUt
-
Algorithmes de remplacement des lignes de cache
Il existe différents types de mémoire cache, dont l'organisation amène des situations où une ligne de la mémoire principale est mappé sur un ensemble de lignes de mémoire cache remplie. Il faut donc choisir la ligne de mémoire cache qui sera remplacée par la nouvelle ligne. Cette sélection est réalisée par les algorithmes de remplacement de lignes de cache. Le principe de fonctionnement de la majorité de ces algorithmes repose sur le principe de localité. Ces algorithmes sont en général divisés en deux grandes catégories :
- les algorithmes dépendants de l'utilisation des données: LRU, LFU, etc…
- les algorithmes indépendants de l'utilisation des données : aléatoire, FIFO.
Sommaire
Algorithme optimal
Cet algorithme, formalisé par L.A. Belady[1], utilise la mémoire cache de manière optimale : il remplace la ligne de mémoire cache qui ne sera pas utilisée pour la plus grande période de temps. Par conséquent, cet algorithme doit connaître les accès futurs afin de désigner la ligne à évincer. Cela est donc impossible à réaliser dans un système réel mais constitue néanmoins un excellent moyen afin de mesurer l'efficacité d'un algorithme de remplacement en fournissant une référence.
Algorithmes usuels
LRU (Least Recently Used)
Cet algorithme remplace la ligne utilisée le moins récemment. L'idée sous-jacente est de garder les données récemment utilisées, conformément au principe de localité. Tous les accès aux différentes lignes de la mémoire cache sont enregistrés ; ce qui explique que cet algorithme coûte cher en termes d'opérations de traitement de liste. De plus, ce coût, qui est un élément vital des systèmes embarqués notamment, augmente exponentiellement avec le nombre de voies de la mémoire cache.
Plusieurs implémentations de cet algorithme sont possibles. L'une d'entre elles est assez simple et se fonde sur l'utilisation d'une matrice triangulaire NxN (où N est le nombre de voies de la mémoire cache). Quand une ligne i est référencée, la ligne i de la matrice est fixée à 1 et la colonne i à 0. La ligne accédée le moins récemment est ainsi la ligne dont la ligne est entièrement égale à 0 et dont la colonne est entièrement égale à 1. Cette définition peut paraître étrange mais par ligne et colonne de la matrice triangulaire, il est entendu tous les éléments non nuls par définition de la matrice (i.e. pour lesquels le numéro de ligne est inférieur au numéro de colonne). Cet algorithme s'exécute rapidement et est assez facile à implémenter en hardware mais sa complexité croît rapidement avec la taille de la mémoire cache. Ainsi, avoir un nombre de voies limité semble préférable mais un faible nombre de voies est source de nombreux conflits… La solution n'est donc pas évidente.
FIFO (First In First Out)
Article détaillé : First in, first out.Comme il vient d'être présenté, l'implémentation de l'algorithme LRU est compliquée pour un nombre de voies important. Une approximation de cet algorithme a donc été développée, il s'agit d'un algorithme FIFO : les lignes de la mémoire cache sont effacées dans l'ordre où elles sont arrivées dans la mémoire cache, utilisant ainsi le principe de localité de la manière la plus simple possible. Cette simplicité de conception, qui lui a valu un franc succès dans l'industrie, est malheureusement obtenue au détriment de l'efficacité. Ainsi, selon Smith[2], le nombre de défauts de cache obtenus par cet algorithme est entre 12 et 20 % plus important que pour le LRU.
L'implémentation hardware est assez simple car elle ne requiert que log2(Nvoies) bits par ensemble de lignes de mémoire cache. Ces bits permettent de désigner la ligne à évincer. Ce compteur est incrémenté à chaque défaut de cache. Si le compteur est initialisé à 0 lors d'un nettoyage de cache, les lignes sont ainsi évincées dans l'ordre où elles ont été enregistrées dans le cache. Cette relation d'ordre n'est valable que pour deux lignes d'un même ensemble.
Malgré sa simplicité, cet algorithme présente l'inconvénient majeur de ne pas relier directement performance et taille de la mémoire cache. Ainsi augmenter la taille du cache peut avoir un effet négatif sur la performance pour certaines séquences d'accès. Ce phénomène est connu sous le nom d'anomalie de Belady.
Algorithme aléatoire
L'algorithme aléatoire est le plus simple : la ligne évincée est choisie au hasard. Cette méthode ne requiert que peu de ressources mais son efficacité est limitée car elle n'est pas fondée sur l'usage des données. Cela peut être implémenté de manière assez simple à l'aide de registres à décalage avec rétroaction linéaire. Selon Al-Zoubi et al[3]., cet algorithme est en moyenne 22% moins efficace que LRU.
Cet algorithme possède un avantage indéniable sur l'algorithme FIFO car ses variations dépendent faiblement de la taille de l'ensemble des données, du nombre de lignes de cache…
LFU (Least Frequently Used)
Alors que LRU enregistre l'ordre d'accès des différentes lignes de mémoire cache, LFU quant à lui garde trace de la fréquence d'accès de ces lignes et remplace la moins fréquemment utilisée. Le point faible de cet algorithme est une pollution du cache. En effet, des lignes qui ont été accédées très fréquemment mais qui ne sont plus utilisées dans le futur tendent à rester dans la mémoire cache. Une solution habituelle est l'ajout d'une politique d'ancienneté : au-delà d'un certain temps, la ligne est désignée comme ligne à remplacer. Néanmoins, en raison de sa complexité d'implémentation, cet algorithme est peu utilisé dans l'industrie.
Approximations de l'algorithme LRU
En raison de la complexité d'implémentation de l'algorithme LRU, qui influe de manière négative sur le temps moyen d'accès à la mémoire cache, des approximations de l'algorithme LRU ont été développées afin de pallier ces problèmes. Les différents algorithmes présentés dans cette section utilisent toutes le fait que dans le bas de la liste d'accès, la probabilité que le processeur requiert une de ces lignes est quasiment identique. Par conséquent, désigner une de ces lignes pour l'éviction donne des résultats très proches. Un ordre partiel à l'intérieur de ces ensembles est donc suffisant.
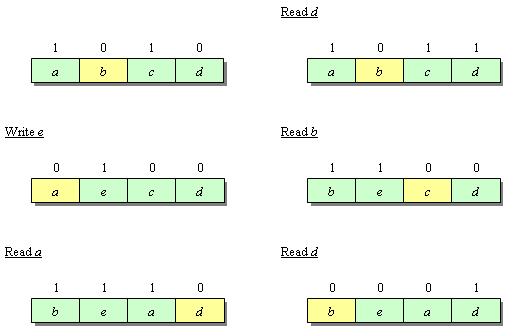
Toutes les figures dessinées ici respectent la convention suivante : le vert correspond à des lignes protégées de l'éviction et le jaune aux lignes considérées comme LRU.
PLRUt (Arbre de décision binaire)
La première approximation est fondée sur un arbre de décision binaire. Elle ne requiert que N-1 bits par ensemble dans un cache associatif de N voies. Ces différents bits pointent la ligne considérée comme pseudo-LRU. Les bits de l'arbre de décision binaire pointant sur la voie hitée sont inversés pour protéger cette ligne de l'éviction. Prenons l'exemple d'un cache de 4 voies représenté sur la figure ci-dessous. Chaque dessin correspond au résultat de l'accès mémoire présenté.
La nature binaire de cet algorithme est également la faiblesse de l'algorithme : le nœud en haut de l'arbre binaire ne contient qu'une information et ne peut donc pas refléter suffisamment bien l'histoire des différentes voies.
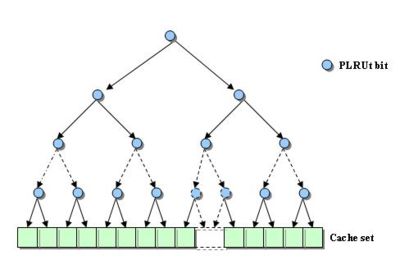 Arbre de décision binaire de PLRUt
Arbre de décision binaire de PLRUt
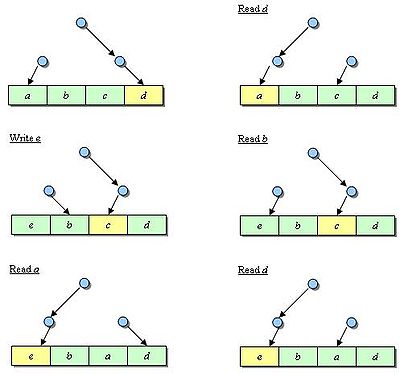 Séquence avec l'algorithme PLRUt
Séquence avec l'algorithme PLRUtPLRUm
À chaque ligne de mémoire cache est assigné un bit. Lorsqu'une ligne est écrite, son bit est mis à 1. Si tous les bits d'un ensemble sont égaux à 1, tous les bits sauf le dernier sont réinitialisés à zéro. Cet algorithme est populaire dans de nombreux caches. Selon Al-Zoubi et al.[3], ces deux pseudo-algorithmes sont de très bonnes approximations et PLRUm donne même de meilleurs résultats que LRU sur certains algorithmes.
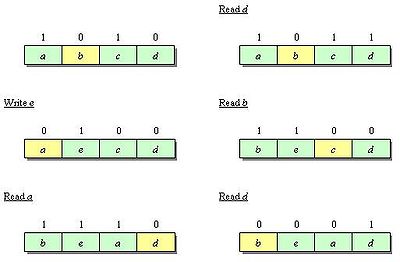 Séquence avec l'algorithme PLRUm
Séquence avec l'algorithme PLRUm1-bit
C'est probablement la plus simple des approximations de l'algorithme LRU et ne requiert qu'un bit par ensemble. Ce bit partage l'ensemble en deux groupes :
- l'un qui contient le MRU (Most Recently Used)
- l'autre non.
Lors d'un hit ou d'un défaut de cache, ce bit est réévalué pour pointer sur la moitié qui ne contient pas le MRU. La ligne à remplacer est ensuité choisie au hasard parmi ce groupe.
LRU améliorés
Les algorithmes LRU et pseudo-LRU fonctionnent bien mais sont faiblement efficaces lors d'accès en burst : les données qui ne sont accédées qu'une fois occupent la mémoire cache et polluent donc cette dernière. Les algorithmes LRU améliorés tentent de résoudre ce problème. Ces algorithmes sont donc très utiles pour les caches de disque ou les copies de fichiers. Tous les algorithmes présentés dans cette section utilisent la même idée : partitionner le cache en deux parties :
- l'une contient les données utilisées une et une seule fois,
- l'autre les données utilisées au moins deux fois.
Les tailles relatives de ces deux groupes sont fixes ou dynamiques, suivant les algorithmes.
2Q
L'idée de cet algorithme est de créer deux queues de taille fixe afin d'éviter la pollution de la mémoire cache. La première liste, qui contient les données accédées une seule fois, est gérée comme une liste FIFO et la seconde comme une liste LRU. La première queue est également partitionnée en deux sous-queues A1in et A1out car les résultats expérimentaux démontrent que la taille optimale de cette queue dépend fortement de la trace.
Selon John et al[4]., cet algorithme donne de meilleurs résultats que LRU, de l'ordre de 5-10%. Le problème est que deux queues doivent êtres gérées ainsi que les migrations de l'une à l'autre ; ce qui requiert beaucoup de hardware et consomme de nombreux cycles d'horloge et d'énergie. Ces raisons expliquent que cet algorithme n'apparaît pas dans les systèmes embarqués mais est une solution utilisée dans les mémoires caches de disque.
LRU-K
Cet algorithme, proposé par O'Neil et al[5]., découpe la mémoire cache en différents groupes qui correspondent aux lignes qui ont été accédées récemment entre 1 et K fois. L'idée de base est la même que celle présentée pour l'algorithme 2Q. Un historique des K derniers accès de chaque ligne de la mémoire principale doit donc être maintenue, ce qui nécessite beaucoup de logique et augmente notablement la consommation. Lors d'un défaut de cache, la ligne à remplacer est choisie en explorant ces listes et en cherchant la donnée qui n'a pas été accédée récemment et dont le K-ème accès est la LRU de la liste K. Cependant, cet algorithme n'est réellement justifié que pour les caches de taille importante.
Voir aussi
Notes
- ↑ L.A. Belady, A study of replacement algorithms for a virtual-storage computer, IBM Systems Journal, Vol. 5, N.2, 1966
- ↑ J.E. Smith and J.R. Goodman, A study of instruction cache organizations and replacement policies, SIGARCH Computer Architecture News, Vol. 11, N. 3, ACM Press, pp. 132-137, 1983
- ↑ a et b H. Al-Zoubi, A. Milenkovic and M. Milenkovic, Performance evaluation of cache replacement policies for the SPEC CPU2000 benchmark suite, ACM-SE 42: Proceedings of the 42nd annual southeast regional conference, ACM Press, pp. 267-272, 2004
- ↑ T. Johnson and D. Shasha, 2Q: A Low Overhead High Performance Buffer Management Replacement Algorithm, VLDB '94: Proceedings of the 20th International Conference on Very Large Data Bases, Morgan Kaufmann Publishers Inc., pp. 439-450, 1994
- ↑ E.J. O'Neil, P.E. O'Neil and G. Weikum, The LRU-K page replacement algorithm for database disk buffering, SIGMOD '93: Proceedings of the 1993 ACM SIGMOD international conference on Management of data, ACM Press, pp. 297-306, 1993
 Portail de l’informatique
Portail de l’informatique
Catégorie : Mémoire informatique

Wikimedia Foundation. 2010.