- N-gramme
-
Un n-gramme est une sous-séquence de n éléments construite à partir d'une séquence donnée. L'idée semble provenir des travaux de Claude Shannon en théorie de l'information. Son idée était que, à partir d'une séquence de lettres donnée (par exemple "par exemple") il est possible d'obtenir la fonction de vraisemblance de l'apparition de la lettre suivante. À partir d'un corpus d'apprentissage, il est facile de construire une distribution de probabilité pour la prochaine lettre avec un historique de taille n. Cette modélisation correspond en fait à un modèle de Markov d'ordre n où seules les n dernières observations sont utilisées pour la prédiction de la lettre suivante. Ainsi un bigramme est un modèle de Markov d'ordre 2.
À partir du (court) corpus "par exemple", nous obtenons :
Pas d'historique (unigramme) :
- p : 2 occurrences sur 10 lettres = 1/5 ;
- e : 3 occurrences sur 10 lettres = 3/10 ;
- x : 1 occurrence sur 10 lettres = 1/10 ;
... La somme des probabilités étant nécessairement égale à 1.
Historique de taille 1 (on considère la lettre et un successeur) :
- p-a : 1 occurrence sur 9 couples = 1/9 ;
- p-l : 1 occurrence sur 9 couples = 1/9 ;
- p-e : 0 occurrence sur 9 couples = 0 ;
... La somme des probabilités étant toujours nécessairement égale à 1.
Nous obtenons des probabilités conditionnelles nous permettant de connaître, à partir d'une sous-séquence, la probabilité de la sous-séquence suivante. Dans notre exemple, P(a | p) = 1 / 9 est la probabilité d'apparition de l'élément a sachant que l'élément p est apparu.
À titre d'exemple, le bi-gramme le plus fréquent de la langue française est de, comme dans l'article de, mais aussi comme dans les mots demain, monde ou moderne.
Sommaire
Usage des N-grammes
Les N-grammes sont beaucoup utilisés en traitement automatique du langage naturel mais aussi en traitement du signal. Leur utilisation repose sur l'hypothèse simplificatrice que, étant donnée une séquence de k éléments (
 ) la probabilité de l'apparition d'un élément en position i ne dépend que des n-1 éléments précédents.
) la probabilité de l'apparition d'un élément en position i ne dépend que des n-1 éléments précédents.On a donc P(wi | w1,...,wi − 1) = P(wi | wi − (n − 1),wi − (n − 2),...,wi − 1).
Avec n = 3 (cas du Trigramme), on a P(wi | w1,...,wi − 1) = P(wi | wi − 2,wi − 1).
La probabilité de la séquence :

est transformée en :
 (on notera les deux premiers termes conservés, il n'y a en effet pas d'élément en position 0 et -1 de la séquence. Ceci peut-être corrigé en introduisant des termes vides, mais ça n'a que peu d'importance).
(on notera les deux premiers termes conservés, il n'y a en effet pas d'élément en position 0 et -1 de la séquence. Ceci peut-être corrigé en introduisant des termes vides, mais ça n'a que peu d'importance).Entraînement des N-grammes
Partant de cette hypothèse, il est alors possible d'entrainer les n-grammes à partir d'un corpus. Toujours avec n = 3, il suffit de parcourir le corpus et de noter, pour chaque apparition d'un triplet d'élément (par exemple, pour chaque triplet de caractère ou de mot) le nombre d'apparitions de ce triplet, le nombre d'apparitions du couple en début de triplet et de diviser le premier par le second.
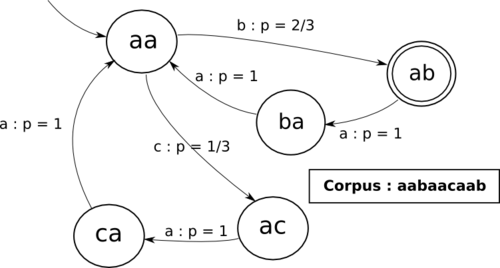
Sur un exemple simple, partant du corpus d'apprentissage "aabaacaab", nous avons les triplets suivants :
- aab
- aba
- baa
- aac
- aca
- caa
- aab
Dénombrons les, ainsi que les couples :
- aab : 2 occurrences
- aba : 1 occurrence
- baa : 1 occurrence
- aac : 1 occurrence
- aca : 1 occurrence
- caa : 1 occurrence
- aa : 3 occurrences
- ab : 2 occurrences
- ba : 1 occurrence
- ac : 1 occurrence
- ca : 1 occurrence
Nous obtenons les tri-grammes suivants :



- ...
À partir de ce corpus, on déduit que, si le couple "aa" apparaît, alors la probabilité que l'élément suivant soit "b" est de 2/3, la probabilité que l'élément suivant soit "c" est de 1/3.Une propriété triviale mais importante est
 . Ceci se généralise trivialement pour toute valeur de n.
. Ceci se généralise trivialement pour toute valeur de n.Nous obtenons la chaîne de Markov équivalente :
Limite des N-grammes
Un premier problème se pose : certains triplets n'apparaissent pas dans le corpus d'apprentissage (leur probabilité est donc fixée à 0) mais risquent d'apparaître à l'utilisation. En effet, on sait qu'il est impossible de construire un corpus suffisamment représentatif pour contenir, de façon justement distribuée (c'est-à-dire correspondant à la distribution réelle) l'ensemble des n-grammes d'un langage (par "langage", nous entendons ici une langue naturelle, mais par extension n'importe quelle ensemble de séquences particulier que l'on voudrait soumettre à l'apprentissage par les n-grammes).
Pour pallier ce problème, les probabilités sont "lissées". Le calcul du tri-gramme est approximé et devient :

avec λ1 + λ2 + λ3 = 1, P(wn − 2) la probabilité de l'unigramme et P(wn − 1 | wn − 2) la probabilité du bi-gramme.
Exploitation des N-grammes
Un exemple complet d'utilisation des N-grammes est présenté dans l'article Algorithme de Viterbi.
Voir aussi
- demo de n-gram
- Algorithme de Viterbi pour un traitement efficace de l'information à l'aide de n-gramme.
- Modèle de Markov caché
Wikimedia Foundation. 2010.