- Lexical markup framework
-
Lexical Markup Framework (LMF ou cadre de balisage lexical, en français) est le standard de l'Organisation internationale de normalisation (plus spécifiquement au sein de l'ISO/TC37) pour les lexiques du traitement automatique des langues (TAL). L'objectif est la normalisation des principes et méthodes relatifs aux ressources langagières dans le contexte de la communication multilingue et de la diversité culturelle.
Sommaire
Objectifs de LMF
L'objectif est de fournir un modèle commun pour la création et l'utilisation des ressources langagières, de gérer l'échange des données entre ces ressources et de permettre la fusion d'un grand nombre de ressources électroniques afin de constituer un vaste réseau de descriptions linguistiques.
Les différents types d'instanciation de LMF peuvent inclure des ressources monolingues, bilingues aussi bien que multilingues. Les mêmes spécifications valent pour les petits et grands lexiques, pour les structures simples comme complexes, pour les ressources lexicales de l'écrit comme de l'oral. Les descriptions couvrent aussi bien la morphologie, la syntaxe, la sémantique que les notations multilingues. Les langues ciblées ne se limitent pas aux langues européennes mais couvrent toutes les langues naturelles. LMF est capable de réprésenter la plupart des lexiques, incluant les lexiques WordNet, EDR et PAROLE.
Historique du projet LMF
Dans le passé, la standardisation a été étudiée et implémentée dans des projets comme GENELEX, EDR, EAGLES, MULTEXT, PAROLE, SIMPLE et ISLE. Puis, les délégations de l'ISO/TC37 décidèrent de travailler sur les normes pour le TAL et les représentations lexicales. Le projet LMF commença durant l'été 2003 par une proposition de nouveau travail (i.e. New Work Item Proposal) de la part de la délégation américaine sur les lexiques électroniques en général. Durant l'automne 2003, la délégation française avec l'aide de l'AFNOR, produisit une proposition technique spécifiquement destinée aux lexiques du TAL. Au début 2004, le comité ISO/TC37 décida de former un projet ISO commun avec Nicoletta Calzolari (Italie) en tant qu'animatrice, Gil Francopoulo (France) et Monte George (USA) en tant qu'éditeurs.
La première étape a été de collecter les descriptions des dictionnaires les plus connus et ensuite, de forger une terminologie commune à ces différents lexiques. L'étape suivante a été de concevoir un modèle capable de représenter ces dictionnaires en détail. Les éditeurs et un groupe de soixante experts ont contribué à cette tâche pour élaborer un modèle consensuel. Une attention spécifique a été apportée à la morphologie afin de mettre en place des dispositifs puissants pour couvrir des langues qui sont réputées difficiles. Treize versions du document de spécification ont été écrites, distribuées (aux experts nommés par les délégations Nationales), commentées et discutées. Après cinq années de travail, incluant de nombreuses réunions physiques et quantité de courriels, les éditeurs sont arrivés à un modèle UML cohérent.
En conclusion, LMF peut véritablement être considéré comme un état de l'art des lexiques du traitement automatique de la langue.
Depuis 2008
La dénomination ISO est 24613. Le document de spécification LMF a été publié officiellement le 17 novembre 2008.
LMF en tant que membre de la famille de standards du TC/37
Les standards de l'ISO/TC37 sont actuellement élaborés en tant que spécifications de haut niveau et traitent de la segmentation des mots (ISO 24614), des annotations (ISO 24611 alias MAF, ISO 24612 alias LAF, ISO 24615 alias SynAF et ISO 24617-1 alias SemAF/Time), des structures de traits (ISO 24610), des conteneurs multimédia (ISO 24616 alias MLIF) et des lexiques (ISO 24613). Ces standards sont fondés sur des spécifications de bas niveau dédiées aux constantes telles que les catégories de données (révision de l'ISO 12620), les codes des langues (ISO 639), les codes des scripts (ISO 15924), les codes des pays (ISO 3166) et Unicode (ISO 10646).
Cette organisation à deux niveaux forme une famille cohérente de standards avec les règles suivantes :
- la spécification de haut niveau fournit les éléments structurels qui sont décorés par les constantes standardisées,
- les spécifications de bas niveau fournissent les constantes standardisées sous forme de métadonnées.
Les standards importants utilisés par LMF
Les constantes linguistiques comme /feminine/ ou /transitive/ ne sont pas définies au sein de LMF mais sont enregistrées dans le registre de catégories de données (Data Category Registry ou DCR, en anglais) qui est géré en tant que ressource globale par l'ISO/TC37 conformément à l'ISO/IEC 11179-3:2003 hal.inria.fr . Et ces constantes sont utilisées pour décorer les éléments structurels de haut niveau.
La spécification LMF respecte les principes de modélisation de Unified Modeling Language (UML) tels que définis par l'Object Management Group (OMG). La structure est spécifiée au moyen de diagrammes de classe UML. Les exemples sont présentés par des diagrammes d'instance (ou objet) UML.
Ajoutons qu'une DTD XML figure en annexe du document LMF.
Structure du modèle
LMF comprend les composants suivants :
- Le modèle noyau qui est l'épine dorsale d'une entrée lexicale,
- les extensions qui décrivent des ressources lexicales spécifiques en réutilisant les composants du noyau avec éventuellement des réquisits additionnels.
Les extensions sont spécifiquement dédiées à la morphologie, aux MRD, à la syntaxe en TAL, à la sémantique en TAL, aux notations multilingues, aux patrons des paradigmes, aux patrons des expressions multimots et aux patrons d'expression des contraintes.
Un exemple simple
Dans l'exemple suivant, l'entrée lexicale est associée à un lemme clergyman et deux formes fléchies clergyman et clergymen. Le codage de la langue est effectuée pour la totalité de la ressource lexicale. La valeur choisie est affectée pour la totalité du lexique comme présenté dans le diagramme d'instance UML suivant :
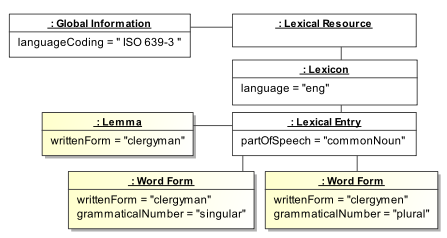
Les éléments Lexical Resource, Global Information, Lexicon, Lexical Entry, Lemma et Word Form definissent la structure du lexique. Ils sont spécifiés dans le document LMF. Au contraire, languageCoding, language, partOfSpeech, commonNoun, writtenForm, grammaticalNumber, singular, plural sont des catégories de données qui sont prises dans le registre des catégories de données. Ces marques décorent la structure. Les valeurs ISO 639-3, clergyman, clergymen sont des chaînes de caractères brutes. La valeur eng est prise dans la liste des langues définie par l'ISO 639-3.
Avec quelques informations additionnelles comme dtdVersion et feat, la même information peut être exprimée par le fragment XML suivant :
<LexicalResource dtdVersion="15"> <GlobalInformation> <feat att="languageCoding" val="ISO 639-3"/> </GlobalInformation> <Lexicon> <feat att="language" val="eng"/> <LexicalEntry> <feat att="partOfSpeech" val="commonNoun"/> <Lemma> <feat att="writtenForm" val="clergyman"/> </Lemma> <WordForm> <feat att="writtenForm" val="clergyman"/> <feat att="grammaticalNumber" val="singular"/> </WordForm> <WordForm> <feat att="writtenForm" val="clergymen"/> <feat att="grammaticalNumber" val="plural"/> </WordForm> </LexicalEntry> </Lexicon> </LexicalResource>
Cet exemple est plutôt simple. LMF est capable de représenter des descriptions linguistiques plus complexes, mais dans ce cas, le balisage XML est plus complexe.
Liens externes
Sites web
Quelques communications scientifiques récentes au sujet de LMF
- Language Resources and Evaluation / Springer Verlag 2008 (DOI: 10.1007/s10579-008-9077-5): Multilingual resources for NLP in the lexical markup framework (LMF)
- Gesellschaft für linguistische Datenverarbeitung GLDV-2007/Tubingen: Lexical Markup Framework ISO standard for semantic information in NLP lexicons hal.inria.fr
- Language Resources and Evaluation LREC-2006/Genoa: Lexical Markup Framework (LMF) hal.inria.fr
Quelques communications connexes
- Language Resources and Evaluation LREC-2006/Genoa: The relevance of standards for research infrastructures hal.inria.fr

Wikimedia Foundation. 2010.