- LFG
-
Grammaire lexicale-fonctionnelle
Le formalisme des grammaires lexicales-fonctionnelles (en anglais Lexical-Functional Grammars, d'où l'acronyme que nous utiliserons désormais, LFG) est un formalisme grammatical utilisé pour formaliser les langues naturelles. C'est un formalisme à décorations dont le formalisme squelette est celui des grammaires non contextuelles, et dont les décorations sont appelées structures fonctionnelles[1]. Historiquement, la définition du modèle par Kaplan et Bresnan au début des années 1980 procède d'une critique des grammaires génératives transformationnelles, en vogue à l'époque, mais dont les trois principaux points faibles étaient leur complexité excessive, leur difficulté à rendre compte des langues à ordre plus libre, et leur inadéquation aux expériences psycholinguistiques censées au contraire plaider en leur faveur.
Sommaire
Idée générale
L'idée sous-jacente à LFG est qu'il n'y a pas nécessairement superposition des fonctions grammaticales avec les positions syntaxiques, pour au moins deux raisons:
- les fonctions grammaticales induisent un graphe de dépendances syntaxiques qui n'est pas nécessairement un arbre, alors que les positions syntaxiques induisent une structure d'arbre,
- une même position syntaxique peut être remplie par la réalisation de diverses fonctions syntaxiques.
Les fonctions grammaticales sont de ce fait des fondamentaux de la théorie LFG, au même titre que les constituants. Les constituants sont donc gérés par le squelette syntaxique non contextuel[2], et les fonctions grammaticales sont gérées par des équations fonctionnelles qui reposent sur l'unification. Une analyse LFG est donc d'une part un arbre de constituants, appelé structure de constituants ou c-structure, et d'autre part une structure fonctionnelle, ou f-structure, qui est une structure de traits dont nous allons maintenant montrer le contenu et la construction.
Règles de grammaire et construction des structures
Soit une règle du squelette, par exemple
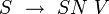 . À chaque non-terminal, de partie droite comme de partie gauche, est associée une f-structure (si S est l'axiome, sa f-structure est la f-structure complète; les autres non-terminaux n'ont qu'une f-structure partielle). Les décorations associées à cette règle squelette définissent par unification la f-structure de S, notée
. À chaque non-terminal, de partie droite comme de partie gauche, est associée une f-structure (si S est l'axiome, sa f-structure est la f-structure complète; les autres non-terminaux n'ont qu'une f-structure partielle). Les décorations associées à cette règle squelette définissent par unification la f-structure de S, notée  , en fonction de celle de SN et de celle de V. Pour cela, on note sous chaque non-terminal les équations où sa f-structure intervient, équations dans lesquelles cette f-structure est notée
, en fonction de celle de SN et de celle de V. Pour cela, on note sous chaque non-terminal les équations où sa f-structure intervient, équations dans lesquelles cette f-structure est notée  . L'opérateur = note l'unification. Une façon raisonnable de décorer la règle squelette ci-dessus est donc par exemple:
. L'opérateur = note l'unification. Une façon raisonnable de décorer la règle squelette ci-dessus est donc par exemple: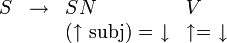
Il s'avère pourtant que cette notation, qui positionne des règles sous chaque non-terminal, n'est pas toujours la plus pratique, bien qu'elle soit souvent très lisible. Nous utiliserons donc une autre notation, où toutes les équations sont les unes en dessous des autres, et où on identifie la f-structure du i-ième non-terminal de partie droite par
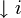 . On notera donc la règle LFG précédente sous la forme suivante:
. On notera donc la règle LFG précédente sous la forme suivante: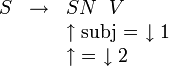
Certaines règles comportent seulement un mot en partie droite, ce sont les règles lexicales. En voici deux exemples:

Les attributs utilisés dans ces règles sont standards, à l'exception de l'attribut pred, qui a une signification spéciale. La valeur d'un pred commence par un identifiant de l'unité sémantique véhiculée par la tête de la structure. Il est le cas échéant suivi d'un cadre de sous-catégorisation, constitué d'arguments syntaxiques séparés par des virgules. Différentes classes de réalisations possibles d'un même argument sont séparées par le signe | et un argument facultatif est mis entre parenthèses. Les classes de réalisations possibles d'arguments sont prises dans une liste close comprenant typiquement obj (syntagme nominal ou clitique), vcomp (infinitive objet), scomp (complétive objet), acomp (attribut adjectival), ncomp (attribut nominal), toutes les combinaisons possibles de ces classes de réalisations avec une préposition, notées prep-classe (par exemple de-obj ou pour-acomp, voire à-scomp pour à ce que...), ainsi que subj, et adjunct (modifieurs). La classe adjunct est spéciale en ce sens qu'elle va correspondre dans la f-structure à un attribut dont les valeurs possibles ne sont pas des f-structures mais des listes (éventuellement vides) de f-structures. Enfin, les arguments syntaxiques correspondant à des arguments sémantiques sont mis à l'intérieur de chevrons, les autres sont donnés après (voir un exemple plus bas).
Les règles données jusqu'ici permettent d'analyser la phrase Jean dort, le résultat étant le suivant:

Cette analyse est correcte car la f-structure obtenue vérifie les trois principes suivants:
- Unicité: un même attribut ne peut apparaître qu'une seule fois dans une même sous-f-structure, et deux réalisations d'un même argument sous-catégorisé par le pred d'une sous-f-structure donnée ne peuvent pas coexister dans cette sous-f-structure,
- Cohérence: tout attribut qui est une réalisation d'argument doit être sous-catégorisé par le pred de la sous-f-structure courante,
- Complétude: tout argument sous-catégorisé par le pred d'une sous-f-structure doit avoir une réalisation qui est présente dans cette sous-f-structure.
Outre l'opérateur = qui dénote l'unification, le formalisme définit d'autres opérateurs permettant de vérifier l'existence ou l'absence d'un trait ou d'ajouter une structure dans une liste de structures (qui remplit un attribut adjunct). Un opérateur particulier permet de rendre obligatoire l'unification d'une structure avec une autre qui apporte une certaine valeur à un certain trait. Cet opérateur, noté = c, est appelé unification contrainte. Pour illustrer cet opérateur, voici une entrée possible de la forme verbale faut (du verbe falloir):
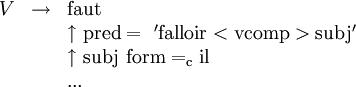
Cette règle ne pourra participer à la construction d'une structure complète que si la sous-f-structure associée au V est unifiée, à un moment donné de l'analyse, avec une autre structure qui lui confère le trait
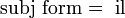 . On note par ailleurs que l'argument subj ne correspondant pas à un argument sémantique, il est placé hors chevrons. C'est ainsi que l'on peut gérer l'impersonnel.
. On note par ailleurs que l'argument subj ne correspondant pas à un argument sémantique, il est placé hors chevrons. C'est ainsi que l'on peut gérer l'impersonnel.Par ailleurs, il peut s'avérer que deux attributs différents (éventuellement de deux sous-f-structures différentes) ont pour valeur la même structure. Cette valeur est alors partagée.
Enfin, on peut dénoter dans une équation non seulement un (sous-)attribut dans une structure mais également un ensemble de (sous-)attributs, chaque analyse devant choisir un des éléments de cet ensemble. Ceci se fait par l'utilisation d'expressions régulières sur les chemins. Par exemple, une équation comme
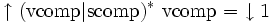 signifie que l'on la f-structure associée au premier symbole de partie droite doit devenir la valeur de l'attribut vcomp de la f-structure associée au symbole de partie gauche ou d'une quelconque de ses sous-f-structures accessible en suivant un chemin ne passant que par des vcomp ou des scomp.
signifie que l'on la f-structure associée au premier symbole de partie droite doit devenir la valeur de l'attribut vcomp de la f-structure associée au symbole de partie gauche ou d'une quelconque de ses sous-f-structures accessible en suivant un chemin ne passant que par des vcomp ou des scomp.Discussion
Le modèle proposé par LFG est séduisant à bien des égards, tant du point de vue de la modélisation de la langue que du point de vue de la lisibilité des grammaires. On peut lui trouver cependant trois inconvénients principaux. Tout d'abord, c'est un formalisme à décorations dont la complexité importante (il est NP-complet) n'est pas triviale à gérer dans des analyseurs efficaces. Ensuite, les constituants sont nécessairement continus. Enfin, il y a quasiment[3] identité entre dépendances syntaxiques et dépendances sémantiques.
Notes et références de l'article
- ↑ Kaplan, R. et Bresnan, J.: Lexical-functional grammar: a formal system for grammatical representation. In The Mental Representation of Grammatical Relations, MIT Press, Cambridge, Massachusetts (pages 173–281), 1982.
- ↑ Il est habituel de considérer que les grammaires non contextuelles ne permettent pas l'optionnalité ou l'opérateur de Kleene sur les non-terminaux de partie droite, alors que le squelette syntaxique de LFG le permet. Ce n'est pourtant qu'une question de notations, puisqu'il y a équivalence forte entre les deux types de grammaires.
- ↑ Les seuls points qui permettent d'entrevoir une distinction sont d'une part la notion d'arguments hors-chevrons dans les cadres de sous-catégorisation, et d'autre part l'ordre dans lequel les arguments sous-catégorisés sont répertoriés, qui peut éventuellement porter du sens.
 Portail de la linguistique
Portail de la linguistique
Catégories : Grammaire | Langage formel | Linguistique générative

Wikimedia Foundation. 2010.