- Algorithme de Knuth-Pratt-Morris
-
Algorithme de Knuth-Morris-Pratt
L'algorithme de Knuth-Morris-Pratt (souvent abrégé par algorithme KMP) est un algorithme de recherche de sous-chaîne, permettant de trouver les occurrences d'une chaîne P dans un texte S. Sa particularité réside en un pré-traitement de la chaîne, qui fournit une information suffisante pour déterminer où continuer la recherche en cas de non-correspondance. Cela permet à l'algorithme de ne pas ré-examiner les caractères qui ont été précédemment vérifiés, et donc de limiter le nombre de comparaisons nécessaires.
L'algorithme a été inventé par Knuth et Pratt, et indépendamment par J. H. Morris en 1975.
Sommaire
Principe de fonctionnement
Approche naïve
Afin de mieux comprendre la logique de l'algorithme de Knuth-Morris-Pratt, il est instructif de se pencher sur l'approche naïve de la recherche de chaîne.
La chaîne B peut être trouvée dans le texte A avec l'algorithme suivant :
- Fixer i = 1 ;
- Tant qu'il reste des positions à vérifier
- Comparer lettre à lettre la chaîne B et le texte A à partir de la position i ;
- Si la chaîne correspond, terminer le traitement et retourner i comme position du début de l'occurrence ;
- Sinon fixer i = i + 1 ;
- Terminer le traitement, aucune occurrence n'a été trouvée.
Cette procédure peut être améliorée en arrêtant la comparaison de la troisième étape dès qu'un caractère différent est détecté.
Cette approche a un inconvénient : après une comparaison infructueuse, la comparaison suivante débutera à la position i + 1, sans tenir aucun compte de celles qui ont déjà eu lieu à l'itération précédente, à la position i. L'algorithme de Knuth-Morris-Pratt examine d'abord la chaîne B et en déduit des informations permettant de ne pas comparer chaque caractère plus d'une fois.
Phases
- La première phase de l'algorithme construit un tableau, indiquant pour chaque position un « décalage », c'est-à-dire la prochaine position où peut se trouver une occurrence potentielle de la chaîne.
- La deuxième phase effectue la recherche à proprement parler, en comparant les caractères de la chaîne et ceux du texte. En cas de différence, il utilise le tableau pour connaître le décalage à prendre en compte pour continuer la recherche sans retour en arrière.
Exemple
Pour présenter le principe de fonctionnement de l'algorithme, un exemple particulier est considéré : la chaîne P vaut ABCDABD et le texte S est ABC ABCDAB ABCDABCDABDE.
Notations : Pour représenter les chaînes de caractères, cet article utilise des tableaux dont les indices débutent à zéro. Ainsi, le C de la chaîne P sera notée P[2]. m désigne la position dans le texte S à laquelle la chaîne P est en cours de vérification, et i la position du caractère actuellement vérifié dans P.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456L'algorithme démarre en testant la correspondance des caractères les uns après les autres. Ainsi, à la quatrième étape, m = 0 et i = 3. S[3] est un espace et P[3] = 'D', la correspondance n'est pas possible.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456Plutôt que de recommencer avec m = 1, l'algorithme remarque qu'aucun A n'est présent dans P entre les positions 0 et 3, à l'exception de la position 0. En conséquence, pour avoir testé tous les caractères précédents, l'algorithme sait qu'il n'a aucune chance de trouver le début d'une correspondance s'il vérifie à nouveau. De ce fait, l'algorithme avance jusqu'au caractère suivant, en posant m = 4 et i = 0.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456Une correspondance presque complète est rapidement obtenue quand, avec i = 6, la vérification échoue.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456Toutefois, juste avant la fin de cette correspondance partielle, l'algorithme est passé sur le motif AB, qui pourrait correspondre au début d'une autre correspondance. Cette information doit donc être prise en compte. Comme l'algorithme sait déjà que ces deux premiers caractères correspondent avec les deux caractères précédant la position courante, il n'est pas nécessaire de les revérifier. Ainsi, l'algorithme reprend son traitement au caractère courant, avec m = 8 et i = 2.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456Cette vérification échoue immédiatement (C ne correspond pas avec l'espace en S[10]). Comme la chaîne ne contient aucun espace (comme dans la première étape), l'algorithme poursuit la recherche avec m = 11 et en réinitialisant i = 0.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456À nouveau, l'algorithme trouve une correspondance partielle ABCDAB, mais le caractère suivant C ne correspond pas au caractère final D de la chaîne.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456Avec le même raisonnement que précédemment, l'algorithme reprend avec m = 15, pour démarrer à la chaîne de deux caractères AB menant à la position courante, en fixant i = 2, nouvelle position courante.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456Cette fois, la correspondance est complète, l'algorithme retourne la position 15 (c'est-à-dire m) comme origine.
1 2 01234567890123456789012 m : v S : ABC ABCDAB ABCDABCDABDE P : ABCDABD i : ^ 0123456L'algorithme de recherche
L'exemple précédent illustre de façon instructive le principe de l'algorithme. Il suppose l'existence d'un tableau donnant les « correspondances partielles » (décrit plus bas), indiquant où chercher le début potentiel de la prochaine occurrence, dans le cas où la vérification de l'occurrence potentielle actuelle échoue. Pour le moment, ce tableau, désigné par T, peut être considéré comme une boîte noire ayant la propriété suivante : si l'on dispose d'une correspondance partielle de S[m] à S[m + i − 1], mais qui échoue lors de la comparaison entre S[m + i] et P[i], alors la prochaine occurrence potentielle démarre à la position m + i − T[i − 1]. En particulier, T[ − 1] existe et est défini à − 1. Étant donné ce tableau, l'algorithme est relativement simple :
- Fixer i = m = 0. Supposons que P a une longueur de n caractères, et S, de l caractères ;
- Si m + i = l, alors terminer le traitement, aucune correspondance n'a été trouvée. Sinon, comparer P[i] et S[m + i] ;
- S'ils sont égaux, fixer i = i + 1. Si i = n, alors la correspondance est complète. Terminer le traitement et retourner m comme position du début de la correspondance ;
- S'ils sont différents, fixer e = T[i − 1]. Fixer m = m + i − e, et si i > 0, fixer i = e ;
- Reprendre à l'étape n° 2.
Cette description met en œuvre l'algorithme appliqué dans l'exemple précédent. À chaque échec de la vérification, le tableau est consulté pour trouver le début de la prochaine occurrence potentielle, et les compteurs sont mis à jour en conséquence. De ce fait, la vérification des caractères n'est jamais effectuée vers l'arrière. En particulier, chaque caractère n'est vérifié qu'une seule fois (bien qu'il puisse être possiblement écarté plusieurs fois suite à l'échec de correspondances. Voir plus bas pour l'analyse de l'efficacité de l'algorithme).
Exemple de code de l'algorithme de recherche
Le morceau de code C qui suit est une implémentation de cet algorithme. Afin de pallier les limitations intrinsèques des tableaux en C, les indices sont décalés d'une unité, c'est-à-dire que T[i] dans le code est équivalent à T[i + 1] dans la description ci-dessus.
int kmp_recherche(char *P, char *S) { extern int T[]; int m = 0; int i = 0; while (S[m + i] != '\0' && P[i] != '\0') // Tant que l'on a pas atteint la fin de la chaîne S ou de la chaîne P. { if (S[m + i] == P[i]) { // Si on a encore une correspondance ++i; // alors on regarde la lettre suivante } else { // sinon m += i - T[i]; /* la prochaine correspondance partielle possible est à T[i] lettre avant celle * qu'on vient de regarder. */ if (i > 0) i = T[i]; /* Puisque l'on sait que les T[i]-1 premières lettres à partir de m sont bonne, * il suffit de regarder P a partir de la T[i]ème position. Pour S on peut * remarquer que on m+i est maintenant égale à (m+i-T[i])+(T[i]) avec les * anciennes valeurs. Ce qui montre qu'on ne retourne pas en arrière. */ } } //Quand on a fini de parcourir une des deux chaines if (P[i] == '\0') { //si la chaine finie est P alors on a trouvé une correspondance à la place m return m; } else { /* Sinon c'est qu'il n'existe pas de correspondance de P dans S donc on renvoie * un nombre impossible */ return m + i; /* m est forcément le nombre de caractère de S, donc m+1 est impossible. On * pourrait aussi renvoyer -1 */ } }
Efficacité de l'algorithme de recherche
En supposant l'existence préalable du tableau T, la phase « recherche » de l'algorithme de Knuth-Morris-Pratt est de complexité O(l), où l désigne la longueur de S. Si l'on exclut les traitements supplémentaires fixes induits par l'entrée et la sortie de la fonction, tous les traitements sont effectués dans la boucle principale. Pour calculer une limite sur le nombre d'itérations, une première observation à propos de la nature de T est nécessaire. Par définition, il est construit de sorte que si une correspondance partielle débutant à S[m] échoue lors de la comparaison entre S[m + i] et P[i], alors la prochaine correspondance potentielle ne débute pas avant S[m + (i − T[i])]. En particulier, la prochaine correspondance potentielle doit se trouver à une position supérieure à m, de sorte que T[i] < i.
Partant de ce fait, on montre que la boucle s'exécute au plus l fois. À chaque itération, elle exécute une des deux branches de l'instruction if.
- La première branche augmente invariablement i et ne modifie pas m, ce qui fait que l'index m + i du caractère actuellement vérifié dans la chaîne S est augmenté.
- La seconde branche ajoute i − T[i] à m. Comme nous l'avons vu, i − T[i] est toujours positif. Ainsi, la position m du début de la correspondance potentielle actuelle est augmentée.
La boucle prend fin si
![S[m + i] = '\backslash 0'](/pictures/frwiki/55/7ebe8adcbdf100ad1412a22fbff2226f.png) , ce qui signifie, en tenant compte de la convention C spécifiant qu'un caractère NUL désigne la fin d'une chaîne, que m + i = l. En conséquence, chaque branche de l'instruction if peut être parcourue au plus l fois, puisqu'elles augmentent respectivement m + i ou m, et que
, ce qui signifie, en tenant compte de la convention C spécifiant qu'un caractère NUL désigne la fin d'une chaîne, que m + i = l. En conséquence, chaque branche de l'instruction if peut être parcourue au plus l fois, puisqu'elles augmentent respectivement m + i ou m, et que 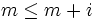 , ainsi si m = l, alors
, ainsi si m = l, alors 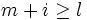 , et comme l'augmentation à chaque itération est au minimum d'une unité, m + i = l a nécessairement été vérifié par le passé.
, et comme l'augmentation à chaque itération est au minimum d'une unité, m + i = l a nécessairement été vérifié par le passé.Ainsi, la boucle est exécutée au plus 2l fois, établissant par là-même une complexité algorithmique en O(l).
Le tableau des « correspondances partielles »
L'objectif de ce tableau est de permettre à l'algorithme ne pas tester chaque caractère du texte plus d'une fois. L'observation-clé, à propos de la nature linéaire de la recherche, qui permet à cet algorithme de fonctionner, est qu'en ayant vérifié une partie du texte avec une « première portion » de la chaîne, il est possible de déterminer à quelles positions peuvent commencer les possibles occurrences qui suivent, et qui continuent de correspondre à la position courante dans le texte. En d'autres termes, les motifs (les sous-parties de la chaîne) sont « pré-recherchés » dans la chaîne, et une liste est établie, indiquant toutes les positions possibles auxquelles continuer pour sauter un maximum de caractères inutiles, sans toutefois sacrifier aucune occurrence potentielle.
Pour chaque position dans la chaîne, il faut déterminer la longueur du motif initial le plus long, qui se termine à la position courante, mais qui ne permet pas une correspondance complète (et qui vient donc très probablement d'échouer). Ainsi, T[i] désigne exactement la longueur du motif initial le plus long se terminant à P[i]. Par convention, la chaîne vide est de longueur nulle. Comme un échec au tout début de la chaîne est un cas particulier (la possibilité de backtracking n'existe pas), on pose T[ − 1] = − 1, tel que discuté précédemment.
En re-considérant l'exemple ABCDABD présenté précédemment, on peut établir qu'il fonctionne sur ce principe, et qu'il bénéficie de la même efficacité pour cette raison. On fixe T[ − 1] = − 1.
-1 0 1 2 3 4 5 6 i : v P[i] : A B C D A B D T[i] : -1Comme P[0] n'apparaît qu'à la fin du motif initial complet, on fixe également T[0] = 0.
-1 0 1 2 3 4 5 6 i : v P[i] : A B C D A B D T[i] : -1 0Pour déterminer T[1], l'algorithme doit trouver un motif terminal dans AB qui soit aussi un motif initial de la chaîne. Mais le seul motif terminal possible de AB est B, qui n'est pas un motif initial de la chaîne. De ce fait, T[1] = 0.
-1 0 1 2 3 4 5 6 i : v P[i] : A B C D A B D T[i] : -1 0 0En poursuivant avec C, on remarque qu'il existe un raccourci pour vérifier tous les motifs terminaux. Considérons que l'algorithme ait trouvé un motif terminal de deux caractères de long, prenant fin sur le C ; alors le premier caractère de ce motif est un motif initial d'un motif initial de la chaîne, et par conséquent, un motif initial lui-même. De plus, il prend fin sur le B, pour lequel nous savons que la correspondance n'est pas possible. Ainsi, il n'est pas nécessaire de se soucier des motifs de deux caractères de longueur, et comme dans le cas précédent, l'unique motif de longueur unitaire ne correspond pas. Donc T[2] = 0.
De même pour D, on obtient T[3] = 0.
-1 0 1 2 3 4 5 6 i : v P[i] : A B C D A B D T[i] : -1 0 0 0 0Pour le A suivant, le principe précédent nous montre que le motif le plus long à prendre en compte contient 1 caractère, et dans ce cas, A correspond. Ainsi, T[4] = 1.
-1 0 1 2 3 4 5 6 i : v P[i] : A B C D A B D T[i] : -1 0 0 0 0 1 P : A B C D A B D P : A B C D A B DLa même logique est appliquée sur B. Si l'algorithme avait trouvé un motif démarrant avant le A précédent, et se poursuivant avec le B actuellement considéré, alors il aurait lui-même un motif initial correct se terminant par A bien que débutant avant A, ce qui contredit le fait que l'algorithme a déjà trouvé que A est la première occurrence d'un motif s'y terminant. En conséquence, il n'est pas nécessaire de regarder avant le A pour y chercher un motif pour B. En fait, en le vérifiant, l'algorithme trouve qu'il continue par B et que B est la deuxième lettre du motif dont A est la première lettre. De ce fait, l'entrée pour B dans T est supérieur d'une unité à celle de A, c'est-à-dire T[5] = 2.
-1 0 1 2 3 4 5 6 i : v P[i] : A B C D A B D T[i] : -1 0 0 0 0 1 2 P : A B C D A B D P : A B C D A B DEnfin, le motif ne continue pas de B vers D. Le raisonnement précédent montre que si un motif d'une longueur supérieure à 1 était trouvé sur D, alors il devrait contenir un motif se terminant sur B. Comme le motif courant ne correspond pas, il doit être plus court. Mais le motif courant est un motif initial de la chaîne se terminant à la deuxième position. Donc ce nouveau motif potentiel devrait lui aussi se terminer à la deuxième position, et nous avons déjà vu qu'il n'y en avait aucun. Comme D n'est pas lui-même un motif, T[6] = 0.
-1 0 1 2 3 4 5 6 i : v P[i] : A B C D A B D T[i] : -1 0 0 0 0 1 2 0D'où le tableau suivant :
i -1 0 1 2 3 4 5 6 P[i] A B C D A B D T[i] -1 0 0 0 0 1 2 0 Algorithme de construction du tableau
L'exemple précédent illustre la technique générale pour produire le tableau avec le moins de soucis possible. Le principe est le même que pour la recherche générale : la majorité du traitement est déjà fait lors de l'arrivée sur un nouvelle position, il ne reste que peu de traitement pour passer à la suivante. Suit la description de l'algorithme. Pour éliminer des cas particuliers, la convention suivante est appliquée : P[ − 1] existe et sa valeur est différente de tous les caractères possibles de P.
- Fixer T[ − 1] = − 1. Supposons que P contienne n caractères ;
- Fixer i = 0 et j = − 1 ;
- Si i = n, terminer le traitement. Sinon, comparer P[i] et P[j].
- S'ils sont égaux, fixer T[i] = j + 1, j = j + 1 et i = i + 1 ;
- Sinon, et si j > 0, fixer j = T[j − 1] ;
- Sinon, fixer T[i] = 0, i = i + 1 et j = 0.
- Reprendre à l'étape n° 3.
Exemple de code de l'algorithme de construction du tableau
Le morceau de code C qui suit est une implémentation de cet algorithme. Comme pour l'algorithme de recherche, les indices de T ont été augmentés de 1 afin de rendre le code C plus naturel. La variable supplémentaire c permet de simuler l'existence de P[ − 1]. Il est supposé que cette fonction, ainsi que la fonction de recherche, sont appelées au sein d'une fonction de niveau supérieur, qui gère convenablement l'allocation de la mémoire pour le tableau T.
void kmp_tableau(char *P) { extern int T[]; int i = 0; int j = -1; char c = '\0'; //Donc c=P[-1] T[0] = j; //c'est à dire -1 while (P[i] != '\0') { //Tant que l'on a pas atteint la fin de la chaine if (P[i] == c) { /* Si P[i]==P[j] donc si le caractère qu'on regarde est le même que le caractère suivant la fin * du dernier motif initial trouvé */ T[i + 1] = j + 1; //alors le motif est continué, et on incrémente i et j. ++j; ++i; } else if (j > 0) { //Sinon si au caractère précédant il existe un motif j = T[j]; //on va regarder le motif initial précédant qui peut correspondre a la lettre où l'on était. } else { /* Sinon j=0 ou -1, i.e. si les lettres qui précédent la ième suivie de la ième ne peuvent * correspondre a aucun marquage initiale */ T[i + 1] = 0; //alors on indique qu'il n'y a aucun motif initiale pour cette lettre. ++i; j = 0; //Cet affectation ne sert en fait que lorsque j=-1. } c = P[j]; } }
Cependant, remplacer int j=-1; par int j=0;, T[0] = j; par T[0] = -1; permettrait de supprimer l'affectation j = 0; sans rien changer au résultat de l'algorithme. On gagne un petit peu de temps d'exécution mais on perd de la cohérence parmi les variables.
Efficacité de l'algorithme de construction du tableau
La complexité de l'algorithme de construction du tableau est O(n), où n désigne la longueur de P. À l'exception des initialisations, tout le traitement est effectué dans l'étape n° 3. Ainsi, il suffit de montrer que cette étape s'exécute en O(n), ce qui est fait par la suite en examinant simultanément les quantités i et i − j.
- Dans la première branche, i − j est préservé, car i et j sont augmentés simultanément. La quantité i, elle, est donc augmentée.
- Dans la deuxième branche, j est remplacé par T[j − 1], qui est toujours strictement inférieur à j (voir plus haut), ce qui augmente i − j.
- Dans la troisième branche, i est augmenté, mais pas j, donc i et i − j sont tous deux augmentés.
Comme
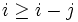 , cela signifie qu'à chaque étape, soit i, soit une quantité inférieure à i augmente. Par conséquent, puisque l'algorithme s'arrête quand i = n, il s'arrête après au plus n itérations de l'étape n° 3, car i − j commence à 1. Ainsi, La complexité de cet algorithme est O(n).
, cela signifie qu'à chaque étape, soit i, soit une quantité inférieure à i augmente. Par conséquent, puisque l'algorithme s'arrête quand i = n, il s'arrête après au plus n itérations de l'étape n° 3, car i − j commence à 1. Ainsi, La complexité de cet algorithme est O(n).Efficacité de l'algorithme de Knuth-Morris-Pratt
Comme les deux parties de l'algorithme ont respectivement des complexités de O(l) et O(n), la complexité de l'algorithme dans sa totalité est O(n + l).
Voir aussi
Articles connexes
Bibliographie
- (en) Donald Knuth, James H. Morris, Jr. et Vaughan Pratt. Fast pattern matching in strings. SIAM Journal on Computing, 6(2):323–350. 1977. Citations. Publication originale.
- (en) Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest et Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0262032937. Section 32.4: The Knuth-Morris-Pratt algorithm, pp.923–931.
Liens externes
- (en) Une explication de l'algorithme.
- (en) Un exemple de l'algorithme Knuth-Morris-Pratt, sur la page Internet de J Strother Moore, co-inventeur de l'algorithme de Boyer-Moore.
- (en) Une page consacrée à l'algorithme, sur un site dévolu aux algorithmes de texte.
 Portail de l’informatique
Portail de l’informatique
Catégorie : Algorithme sur les chaînes de caractères
Wikimedia Foundation. 2010.