- Tf-idf
-
TF-IDF
Le tf-idf ou TF-IDF (de l'anglais term frequency-inverse document frequency) est une méthode de pondération souvent utilisée dans la fouille de textes. Cette mesure statistique permet d'évaluer l'importance d'un mot par rapport à un document extrait d'une collection ou d'un corpus. Le poids augmente proportionnellement en fonction du nombre d'occurrences du mot dans le document. Il varie également en fonction de la fréquence du mot dans le corpus. Des variantes de la formule originale sont souvent utilisées dans des moteurs de recherche pour apprécier la pertinence d'un document en fonction des critères de recherche de l'utilisateur.
Sommaire
Définition formelle
Fréquence du terme
La fréquence du terme (term frequency) est simplement le nombre d'occurrences de ce terme dans le document considéré. Cette somme est en général normalisée pour éviter les biais liés à la longueur du document (le nombre d'occurrences serait potentiellement plus élevé dans une page que dans un paragraphe).
Soit le document dj et le terme ti, alors la fréquence du terme dans le document est :
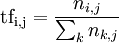
où ni,j est le nombre d'occurrences du terme ti dans dj. Le dénominateur est le nombre d'occurrences de tous les termes dans le document dj.
Fréquence inverse de document
La fréquence inverse de document (inverse document frequency) est une mesure de l'importance du terme dans l'ensemble du corpus. Elle consiste à calculer le logarithme de l'inverse de la proportion de documents du corpus qui contiennent le terme :
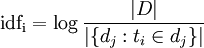
où
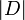 : nombre total de documents dans le corpus
: nombre total de documents dans le corpus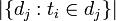 : nombre de documents où le terme ti apparaît (c'est à dire
: nombre de documents où le terme ti apparaît (c'est à dire 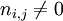 ).
).
Calcul de tf-idf
Finalement, le poids s'obtient en multipliant les deux mesures :
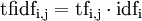
Exemple
Corpus (tiré d'œuvres de Friedrich Gottlieb Klopstock) [1] Document 1 Document 2 Document 3 Son nom est célébré par le bocage qui frémit, et par le ruisseau qui murmure, les vents l’emportent jusqu’à l’arc céleste, l’arc de grâce et de consolation que sa main tendit dans les nuages. À peine distinguait-on deux buts à l’extrémité de la carrière : des chênes ombrageaient l’un, autour de l’autre des palmiers se dessinaient dans l’éclat du soir. Ah ! le beau temps de mes travaux poétiques ! les beaux jours que j’ai passés près de toi ! Les premiers, inépuisables de joie, de paix et de liberté ; les derniers, empreints d’une mélancolie qui eut bien aussi ses charmes. L'exemple porte sur le document 1 (soit d1) et le terme analysé est « qui » (soit t1 = qui). La ponctuation et l'apostrophe sont ignorées.
Calcul de tf
Détails du calcul : la plupart des termes apparaissent une fois (21 termes), l apparaît 3 fois et arc, de, et, le, les, par et qui (2 fois). Le dénominateur est donc 3 + 7*2 + 21 =38. Cette somme est le nombre de mots dans le document.
Calcul de idf
Le terme « qui » n'apparaît pas dans le deuxième document. Ainsi :
Poids final
On obtient :
Pour les autres documents :
Le premier document apparaît ainsi comme « le plus pertinent ».
Références
- ↑ Textes tirés de Friedrich Gottlieb Klopstock sur Wikisource (Les Constellations, Les Deux Muses et À Schmied, ode écrite pendant une maladie dangereuse)
Bibliographie
- (en) Gerard Salton, M.J. McGill, Introduction to modern information retrieval, 1983 [détail des éditions]
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques Portail de l’informatique
Portail de l’informatique
Catégorie : Traitement automatique du langage naturel
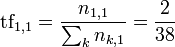
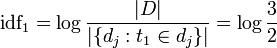
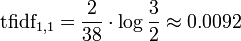
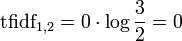
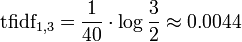
Wikimedia Foundation. 2010.