- Reconnaissance de l'ecriture manuscrite
-
Reconnaissance de l'écriture manuscrite
La reconnaissance de l’écriture manuscrite est un traitement informatique qui a pour but de traduire un texte écrit en un texte codé numériquement.
Il faut distinguer deux reconnaissances distinctes, avec des problématiques et des solutions différentes :
- la reconnaissance en-ligne ;
- la reconnaissance hors-ligne.
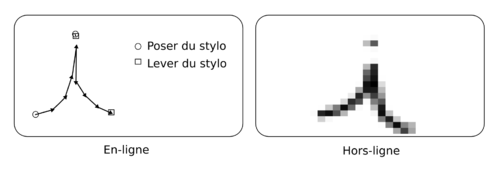
La reconnaissance de l’écriture manuscrite fait appel à la reconnaissance de forme, mais également au traitement automatique du langage naturel. Cela veut dire que le système, tout comme le cerveau humain, reconnaît des mots et des phrases existant dans un langage connu plutôt qu’une succession de caractères. Ceci améliore grandement la robustesse.
Sommaire
Reconnaissance hors-ligne
La reconnaissance hors-ligne travaille sur un instantané d’encre numérique (sur une image). C’est le cas notamment de la Reconnaissance Optique de l’Écriture. Dans ce contexte, il est impossible de savoir comment ont été tracés les différents motifs. Il est seulement possible d’extraire des formes à partir de l’image, en s’appuyant sur les technologies de reconnaissance de forme.
C’est évidemment le type de reconnaissance privilégié pour les traitements asynchrones tels que la lecture de chèque bancaire ou le tri postal.
Reconnaissance en-ligne
Dans le cadre de la reconnaissance en-ligne, l’échantillon d’encre est constitué d’un ensemble de coordonnées ordonnées dans le temps. Il est ainsi possible de suivre le tracé, de connaître les posés et levés de stylo et éventuellement l’inclinaison et la vitesse. Il faut évidemment un matériel spécifique pour saisir un tel échantillon, c’est le cas notamment des stylos numériques ou des stylets sur agendas électroniques ou sur les Tablets PC.
La reconnaissance en-ligne est généralement beaucoup plus efficace que la reconnaissance hors-ligne car les échantillons sont beaucoup plus informatifs. En revanche, elle nécessite un matériel beaucoup plus coûteux et impose de fortes contraintes au scripteur puisque la capture de l’encre doit se faire au moment de la saisie (capture synchrone) et non a posteriori (capture asynchrone).
Les techniques usitées peuvent avoir un champ applicatif plus vaste permettant la reconnaissance de toute forme abstraite simple (cf. Reconnaissance de formes, Intelligence artificielle faible). Les systèmes actuels (en 2005) procèdent majoritairement par une comparaison de l’échantillon à reconnaître avec ceux contenus dans une base de données. Cette base de données peut être créée de toutes pièces ou être l’objet d’une phase d’apprentissage.
Les techniques de comparaison reposent généralement sur des méthodes statistiques simples pour gagner en vitesse de traitement. La conséquence est que le nombre de formes reconnaissables doit être limité, sans quoi les résultats risquent d’être souvent erronés. En effet, toute la difficulté de la reconnaissance est d’évaluer la similarité entre une forme étudiée et chaque forme de la base de données (il est presque impossible qu’il y ait une correspondance exacte). Il suffit alors de choisir la forme la plus similaire. La reconnaissance idéale doit avoir la même évaluation de similarité que le cerveau, ce dont on se rapproche avec les réseaux de neurones. Mais les méthodes plus rapides (moins complexes) évalueront une similarité entachée d’erreur. Lorsqu’il y a peu de formes dans la base de données, bien séparées, la forme la plus similaire restera la même, et donc le résultat final sera juste. En augmentant la taille de la base des données, on « rapproche » nécessairement les formes modèles entre elles, et l’erreur sur la similarité peut plus facilement faire pencher la balance vers une mauvaise forme.
Reconnaissance de forme
La reconnaissance de forme joue un rôle très important dans la reconnaissance de l’écriture (manuscrite/imprimée) à deux niveaux :
Extraction de graphème
La reconnaissance de forme s’applique sur un motif. Il faut donc en premier lieu séparer les différents motifs composant les mots (lettres, chiffres, symboles…) avant de les reconnaître.
Sur l’exemple suivant, les différents points de séparation possibles sont annotés.

Il est évident que toutes les segmentations ne sont pas correctes et que seules certaines doivent être conservées. Il existe donc une ambiguïté qu’il faut lever pour optimiser la reconnaissance.
Reconnaissance de motifs
À partir des graphèmes extraits précédemment, la reconnaissance de forme permet d’obtenir les différents motifs la composant. La reconnaissance de motifs va également assister l’extraction de graphèmes en écartant une partie des segmentations impossible. Ainsi, plus la reconnaissance de motif est efficace et plus la segmentation l’est. De la même façon, une segmentation efficace conduit nécessairement à une meilleure reconnaissance. Il faut segmenter pour reconnaître, et reconnaître pour segmenter.
Assistance du modèle de langage
Il reste beaucoup d’ambiguïtés après les opérations de segmentation et de reconnaissance. Le traitement du langage intervient à ce niveau en écartant les solutions les moins probables, d’un point de vue linguistique.
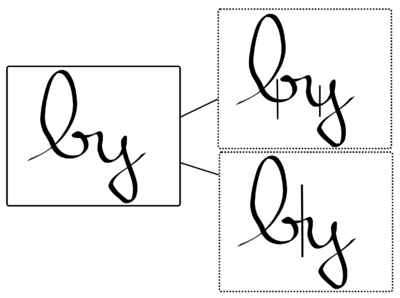
Dans l’exemple précédent, les étapes de segmentations et de reconnaissance de forme ont conduit aux choix « lrj » ou « by ». Le modèle de langage (parfois un simple dictionnaire) choisira vraisemblablement la solution « by » en fonction de la langue. Le modèle de langage peut-être beaucoup plus complexe et reconnaître par exemple des suites de formes (n-grammes). Ainsi « Il est » sera préféré à « Il ont » en cas d’ambiguïté.
Collaboration des traitements
Le déroulement de la reconnaissance n’est pas linéaire : les différents traitements apportant à chaque fois un peu plus d’information sur les solutions probables, il peut être intéressant de reprendre une étape à partir des informations fournies par un traitement précédent pour affiner le résultat. Il y a ainsi une collaboration des différents traitements pour augmenter la fiabilité de la reconnaissance.
A priori sur le langage
Quel que soit le type de reconnaissance de l’écriture, l’affinage du modèle de langage est la clé de l’optimisation. En effet, pour garantir de bons résultats il faut plutôt voir le traitement comme faire un choix de solution(s) parmi un ensemble de choix proposé a priori plutôt que de chercher à deviner, à partir de la forme, ce que le scripteur a voulu écrire. Chercher à reconnaître un texte sans aucune information est à ce jour très difficile, alors que chercher à reconnaître le même texte si l’on connaît la langue employée et le registre (prise de note, texte « correct », SMS) est beaucoup plus efficace.
De cette façon, la technologie est suffisamment avancée pour permettre de reconnaître très rapidement et avec une excellente fiabilité l’adresse sur une enveloppe : le système ne cherche pas à reconnaître au hasard une information, mais à extraire un code postal (par exemple, en France : 5 chiffres) parmi tous ceux qu’il connaît. Un nouveau tri par quartier est alors possible : le système cherchera à extraire la rue parmi celles qu’il connaît pour ce code postal…
À titre d’analogie, il est possible pour un être humain de comprendre l’intégralité d’une phrase même lorsqu’une partie est bruité, par exemple le lecteur parviendra sans aucun doute à comprendre la phrase bruitée suivante : « je suis allé au ci*** voir un film », grâce au contexte posé par le reste de la phrase. Ce contexte donne un a priori sur le mot bruité à reconnaître.
Références
- Jean-Pierre Crettez et Guy Lorette, Reconnaissance de l’écriture manuscrite, 1998 (article)
 Portail de l’informatique
Portail de l’informatique
Catégories : Gestion électronique de documents | Traitement d'image | Traitement automatique du langage naturel


Wikimedia Foundation. 2010.