- Architecture federee
-
Architecture fédérée
L'architecture fédérée est une forme d'architecture centrée sur les données. Le terme de système de base de données fédérée a été introduit par Heimbigner et McLeod [1] ils définissent l’essentiel de ce qu’est une base de données fédérée faiblement couplée : « collection of components to unite loosely coupled federation in order to share and exchange information » et une base de données fédérée fortement couplée : « an organization model based on equal, autonomous databases, with sharing controlled by explicit interfaces. »
L’objectif de la création d’une base fédérée est de donner aux utilisateurs une vue unique des données implémentées sur plusieurs systèmes a priori hétérogènes. Il s’agit d’une problématique typique lors de la concentration ou de la fusion d’entreprises : faire cohabiter les différents systèmes tout en leur permettant d’interopérer d’une manière harmonieuse. Il ne s’agit pas ici de reconstruire une base répartie à partir des anciennes (ré-ingénierie), mais de conserver les anciennes bases et leurs autonomies locales tout en permettant l’intégration de l’ensemble.
Sheth et Larson [2] divisent les systèmes fédérés en deux catégories : les systèmes faiblement couplés réalisant l’intégration des différentes bases de données à l’aide des mécanismes des bases de données multibases et réparties (et donc la tâche de maintenir la fédération est laissée aux administrateurs locaux[3]) et les systèmes fortement couplés réalisant l’intégration à l’aide d’un SGBD fédéré (le maintien de la fédération est sous le contrôle de l’administrateur de la fédération).
Sommaire
Les fédérations faiblement couplées
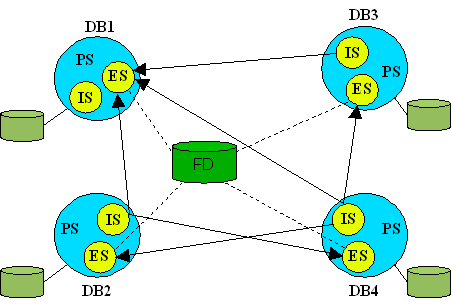
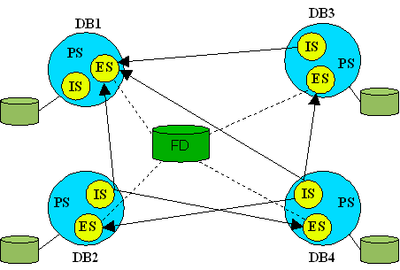 Modèle d'architecture fédérée faiblement couplée
Modèle d'architecture fédérée faiblement couplée
Pour réaliser une telle intégration, quatre schémas sont utilisés dans les bases de données composant la fédération; le schéma d'exportation (ES) pour les données permises à l'exportation, le schéma d'importation (IS) pour les données importées, le schéma privé (PS) pour l'ensemble de données privées (ES et IS inclus) et le schéma commun (global, canonique ou pivot) qui dans le cas des bases de données faiblement couplées n’est qu’une abstraction se trouvant dans le dictionnaire de données de la fédération (FD).
Dans le diagramme, nous avons quatre bases de données distinctes, offrant la portion de leurs données qui est nécessaire à la fédération via leurs ES. Les informations (métadonnées) concernant le schéma global se retrouvent dans la FD. Nous retrouvons également dans la FD les informations indiquant comment effectuer l’importation des données pour réaliser des vues sur le schéma global (liens en pointillés).
Nous voyons dans le diagramme que le schéma global n’existe que d’une façon virtuelle, les différents administrateurs de données locaux doivent créer des vues à la main sur les différents schémas d’exportation pour réaliser une vue totale ou partielle (mais virtuelle) du schéma global. Les schémas d’exportation (ES) sont en général des vues sur une portion de la base locale de manière à permettre la correspondance entre cette portion de la base et le schéma global. Nous constaterons que les schémas originaux restent inchangés et que les utilisateurs locaux peuvent continuer à utiliser leurs anciennes bases comme si de rien n’était. La seule nouveauté pour un usager local est l’accès possible aux données de la fédération via son IS local.
Les fédérations fortement couplées
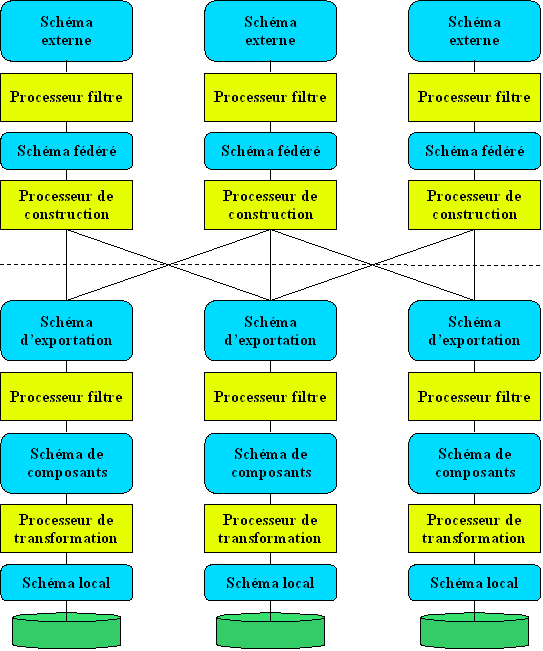
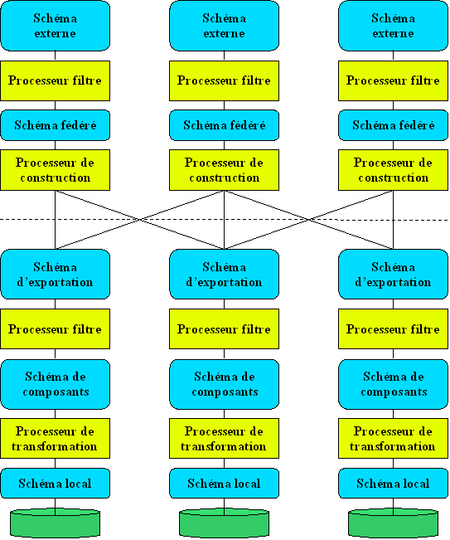 Modèle d'architecture fédérée fortement couplée, d'après Sheth, A.P., Larson, J.: Federated database systems for managing heterogeneous, distributed and autonomous Databases. ACM Computing Surveys, Vol. 22, No. 3, 1990
Modèle d'architecture fédérée fortement couplée, d'après Sheth, A.P., Larson, J.: Federated database systems for managing heterogeneous, distributed and autonomous Databases. ACM Computing Surveys, Vol. 22, No. 3, 1990Pratiquement tous les auteurs dans le domaine de la médiation de données attribuent à [Sheth & Larson, 1990] le concept de fédération de données et en général, le concept de fédération se ramène à l’approche fortement couplée. Pourtant, ces auteurs ont pour seul mérite d’avoir synthétisé et catégorisé les différentes approches fédératives existantes à l’époque et d’avoir proposé une architecture de référence pour l’approche fédérée fortement couplée (sans concevoir de système opérationnel). Voici la listes des systèmes existants à l’époque (selon Sheth et Larson) : ADDS, CALIDA, DQS, DDTS, IISS, Mermaid, MRDSM, Multibase, OMNIBASE.
Il s’agit essentiellement du même diagramme que celui présenté par Sheth et Larson. Seule la ligne pointillée a été rajoutée, celle-ci sépare la partie supérieure que nous baptiserons intégrateur et qui est responsable de l’intégration des différentes BD de la partie inférieure que nous appellerons traducteur, qui permet la traduction d’un schéma d’une BD dans un modèle canonique. Il est naturel de concevoir un déploiement de cette architecture avec les traducteurs sur les mêmes hôtes que les SGBD locaux et l’intégrateur sur un hôte particulier. Un tel système peut être baptisé SGBDF pour Système de Gestion de Bases de Données Fédérées et possède de multiples points en commun avec les SGBD traditionnels et répartis. En fait, nous pouvons considérer ces systèmes comme des SGBD répartis pour lesquels les schémas internes sont des SGBD traditionnels. Il est donc naturel de concevoir un SGBDF comme une évolution des SGBD répartis.
Tous les systèmes de type fédéré fortement couplé suivent d’une manière plus ou moins heureuse l’architecture générique établie par Sheth et Larson. Cette architecture est composée essentiellement de processeurs et de schémas. Voici les différentes catégories de ces composantes dégagées par les deux auteurs et se retrouvant dans le diagramme.
Processeurs de transformations
Ces processeurs traduisent une commande effectuée dans un langage (ex.: SQL) en une requête dans un autre langage (ex. : CODASYL). Pour pouvoir effectuer cette tâche, ils offrent une vision transparente des modèles de données. Ils convertissent donc un schéma conçu selon un modèle en un autre (ex. : modèle réseau en modèle relationnel et vice versa).
Processeurs filtres
Ces processeurs vérifient les commandes envoyées à un processeur ou les résultats retournés par un processeur pour s’assurer qu’ils ne violent pas des règles d’intégrité syntaxique et/ou sémantique. Ces processeurs peuvent s’occuper également de la vérification des droits d’accès aux données. Concrètement, ils sont responsables du maintien de la fédération en offrant des mécanismes explicites permettant de résoudre les contraintes du schéma global.
Processeurs de constructions
Ces processeurs divisent les commandes ou les données envoyées par un processeur en commandes ou données destinées à plusieurs processeurs. Ou encore, à l’inverse, intègrent des commandes ou des données envoyées par plusieurs processeurs. Les tâches pouvant être accomplies par ces processeurs sont les suivantes : intégration de schémas, négociation de protocoles entre processeurs, optimisation de requêtes et décomposition des requêtes pour différents processeurs, gestion des transactions (atomicité et concurrence). Processeurs d’accès : Ces processeurs acceptent les commandes effectuées par différents processeurs et manipulent directement les données en fonction des commandes. Ils correspondent à des SGBD locaux.
Schémas locaux
Ils correspondent aux schémas des bases de données participantes, exprimés dans leurs modèles de données propres (relationnel, réseau, hiérarchique). Schémas des composants : Ils correspondent aux schémas des bases de données participantes une fois que les schémas sont traduits dans un modèle de données commun (pivot). Schémas d’exportation : Ils correspondent à la portion des schémas des composants destinés à l’intégration au sein de la fédération.
Schéma fédéré
Il s’agit du schéma de la fédération proprement dit.
Schémas externes
Équivalents aux schémas externes de l’architecture Ansi/Sparc mais au niveau de la fédération.
Développements actuels et futurs
Actuellement, la norme qui s’impose en matière de SGBDF est conçue par IBM et se nomme DB2 UDB Federated System (supporté par MS SQL server, Oracle et Sybase). Malheureusement, ce système ne supporte pas encore parfaitement l’écriture et est, en général, seulement en lecture seule. L’alternative la plus simple de développement d’une fédération en lecture / écriture (au moins partielle) à l’aide de la technologie existante, semble résider dans le respect absolu des standards relationnels. Dans ce cas, il serait possible d’intégrer différentes bases de données en transférant chacune sur un même modèle de SGBD et en créant notre fédération comme un système de données réparties. L’autonomie des différentes bases de données est conservée car le transfert d’une base de données relationnelle conçue d’une manière standard sur un autre SGBDR ne devrait pas causer de gros problèmes. Le standard SQL-99 intégrant les « triggers » et les fonctions (PL/SQL) permet de créer les conversions et vérifications de contraintes nécessaires au maintien de la fédération. Par contre, l’obligation que tous les membres respectent les standards relationnels semble utopique vu le nombre aberrant de « legacy system » en entreprise.
Si plus de quinze ans après la parution de l’article de Sheth et Larson, aucun véritable produit commercial complet de SGBDF n’existe, cela semble indiquer un sérieux problème avec cette approche : «…plusieurs problèmes restent à résoudre avant que cette approche devienne commercialisable. Ni les aspects de conception (comment construire une vision commune des données partagées), ni les aspects système (où les techniques doivent être adaptées à un environnement distribué) ne sont complètement résolus … L'intégration de bases de données est un problème complexe. Un nombre considérable d'articles en ont étudié différents aspects : il en résulte une multitude de contributions techniques, quelques méthodologies et quelques prototypes. » [4]
La situation actuelle n’a guère changé et l’apparition de l’approche par médiation semble avoir définitivement tué dans l’œuf l’approche par fédération fortement couplée.
Notes et références
- ↑ Heimbigner, D., McLeod, D.: A federated architecture for information management. ACM Transactions on Office Information Systems (TOIS), Vol. 3, No. 3, p253-278, juillet 1985
- ↑ Sheth, A.P., Larson, J.: Federated database systems for managing heterogeneous, distributed and autonomous Databases. ACM Computing Surveys, Vol. 22, No. 3, 1990
- ↑ Litwin, W., Abdelatif, A.: Multidatabase interoperability. IEEE Computer, Vol. 19, No. 12, 1986
- ↑ Parent, P., Spaccapietra, S.: Intégration de bases de données: Panorama des problèmes et des approches. Ingénierie des Systèmes d'Information, Vol.4, No.3, 1996.
Catégorie : Architecture logicielle
Wikimedia Foundation. 2010.