Word recognition rate
- Word recognition rate
-
Taux d'erreur de mots

Pour les articles homonymes, voir
WER.
Le taux d'erreur de mots, ou word error rate (WER) en anglais, est une unité de mesure classique pour mesurer les performances d'un système de reconnaissance vocale.
Le WER est dérivé de la distance de Levenshtein, en travaillant au niveau des mots au lieu des caractères. Il indique le taux de mots incorrectement reconnus par rapport à un texte de référence. Au plus le taux est faible (minimum 0.0) au plus la reconnaissance est bonne. Le taux maximum n'est pas borné et peut dépasser 1.0 en cas de très mauvaise reconnaissance s'il y a beaucoup d'insertions.
Après avoir aligné de manière optimale la référence avec le texte reconnu grâce à un algorithme de programmation dynamique, le taux d'erreur de mots est donné par:
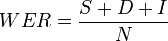
Néanmoins, il est fréquent de rapporter plutôt le taux de reconnaissance de mots, ou word recognition rate (WRR) en anglais, et souvent en pourcentage. Il indique le taux de mots corrects par rapport à un texte de référence. Au plus le taux est élevé, au plus la reconnaissance est de bonne qualité (maximum 100%). Le taux minimum n'est pas borné et peut être négatif.
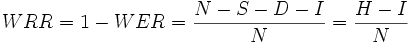
Où :
- N est le nombre de mots de référence,
- S est le nombre de substitutions (mots incorrectement reconnus),
- D est le nombre de suppressions (mots omis),
- I est le nombre d'insertions (mots ajoutés),
- H est le nombre de mots correctement reconnus.
Références
Catégories : Traitement de la parole | Traitement automatique du langage naturel
Wikimedia Foundation.
2010.
Contenu soumis à la licence CC-BY-SA. Source : Article Word recognition rate de Wikipédia en français (auteurs)
Regardez d'autres dictionnaires:
Word error rate — (WER) is a common metric of the performance of a speech recognition system.The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly … Wikipedia
Word error rate — Taux d erreur de mots Pour les articles homonymes, voir WER. Le taux d erreur de mots, ou word error rate (WER) en anglais, est une unité de mesure classique pour mesurer les performances d un système de reconnaissance vocale. Le WER est dérivé… … Wikipédia en Français
Speech recognition — For the human linguistic concept, see Speech perception. The display of the Speech Recognition screensaver on a PC, in which the character responds to questions, e.g. Where are you? or statements, e.g. Hello. Speech recognition (also known as… … Wikipedia
Automatic Speech Recognition — Reconnaissance vocale Pour les articles homonymes, voir ASR. La reconnaissance vocale ou reconnaissance automatique de la parole (Automatic Speech Recognition ASR) est une technologie informatique qui permet d analyser un mot ou une phrase captée … Wikipédia en Français
Optical character recognition — Optical character recognition, usually abbreviated to OCR, is the mechanical or electronic translation of scanned images of handwritten, typewritten or printed text into machine encoded text. It is widely used to convert books and documents into… … Wikipedia
Optical mark recognition — (also called Optical Mark Reading and OMR) is the process of capturing human marked data from document forms such as surveys and tests. Contents 1 OMR background 2 OMR software 2.1 Open Source … Wikipedia
Discount rate — For the interest rate charged to banks for borrowing short term funds directly from the Federal Reserve, see discount window. For the fees charged to merchants for accepting credit cards, see Discount Rate under Merchant Account. For discount… … Wikipedia
Named entity recognition — (NER) (also known as entity identification (EI) and entity extraction) is a subtask of information extraction that seeks to locate and classify atomic elements in text into predefined categories such as the names of persons, organizations,… … Wikipedia
Named-entity recognition — (NER) (also known as entity identification and entity extraction) is a subtask of information extraction that seeks to locate and classify atomic elements in text into predefined categories such as the names of persons, organizations, locations,… … Wikipedia
Taux de reconnaissance de mots — Taux d erreur de mots Pour les articles homonymes, voir WER. Le taux d erreur de mots, ou word error rate (WER) en anglais, est une unité de mesure classique pour mesurer les performances d un système de reconnaissance vocale. Le WER est dérivé… … Wikipédia en Français