- LSH
-
Locality sensitive hashing
Locality Sensitive Hashing (LSH) est une méthode de recherche approximative dans des espaces de grande dimension. C'est une solution au problème de la malédiction de la dimension qui apparait lors d'une recherche des plus proches voisins en grande dimension. L'idée principale est d'utiliser une famille de fonction de hachage choisies telles que des points proches dans l'espace d'origine aient une forte probabilité d'avoir la même valeur de hachage. La méthode a de nombreuses applications en vision artificielle, traitement automatique de la langue, bio-informatique...
Sommaire
Définition
Une famille LSH
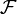 est définie pour un espace métrique
est définie pour un espace métrique 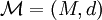 , un seuil R > 0 et un facteur d'approximation c > 1 [1] [2]. est une famille de fonctions
, un seuil R > 0 et un facteur d'approximation c > 1 [1] [2]. est une famille de fonctions 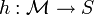 satisfaisant les conditions suivantes pour deux points quelconques
satisfaisant les conditions suivantes pour deux points quelconques 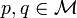 , et une fonction h choisie aléatoirement parmi la famille :
, et une fonction h choisie aléatoirement parmi la famille :- si
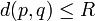 , alors
, alors ![Pr_{h \in H} [h(p) = h(q)] \ge P_1](/pictures/frwiki/101/e48dbc8481e2df39bde5987c0de2a8f7.png)
- si
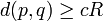 , alors
, alors ![Pr_{h \in H} [h(p) = h(q)] \le P_2](/pictures/frwiki/102/f00ebad58eb9407f4281061cdcd646be.png)
Par construction, les fonctions de hachage doivent permettre aux points proches d'entrer fréquemment en collision (i.e. h(p) = h(q)) et inversement, les points éloignés ne doivent entrer que rarement en collision. Pour que la famille LSH soit intéressante, il faut donc P1 > P2. La famille
est alors appelée (R,cR,P1,P2)-sensitive. La famille est d'autant plus intéressante si P1 est très supérieure à P2. En pratique, on a souvent 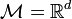 .
.Une définition alternative[3] est définie par rapport à un univers U possédant une fonction de simlarité
![\phi : U \times U \to [0,1]](/pictures/frwiki/51/33b14ac9cf67f9c2f70bcfe923baac13.png) . Une famille LSH est alors un ensemble de fonctions de hachage H et une distribution de probabilité D sur les fonctions, telle qu'une fonction
. Une famille LSH est alors un ensemble de fonctions de hachage H et une distribution de probabilité D sur les fonctions, telle qu'une fonction 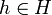 choisie selon D satisfait la propriété
choisie selon D satisfait la propriété ![Pr_{h \in H} [h(a) = h(b)] = \phi(a,b)](/pictures/frwiki/101/ebbc28ce3e44e528fbdc537a6806c382.png) pour tout
pour tout 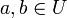 .
.Applications
LSH a été appliqué dans plusieurs domaines, en particulier pour la recherche d'image par le contenu, la comparaison de sequence d'ADN[4], la recherche par similarité de documents audios.
Méthodes
Échantillonnage par bit pour la distance de Hamming
Une façon simple de construire une famille LSH est par échantillonage de bit[2],[5]. Cette approche est adaptée à la distance de Hamming dans un espace binaire de dimension d, i.e. un point de l'espace appartient à {0,1}d. La famille
de fonctions de hachage est alors simplement l'ensemble des projections sur une des d coordonnées, i.e., 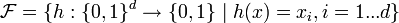 , où xi est la ie coordonnée de x. Une fonction aléatoire h de
, où xi est la ie coordonnée de x. Une fonction aléatoire h de 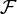 ne fait donc que sélectionner un bit au hasard dans le vecteur x d'origine.
ne fait donc que sélectionner un bit au hasard dans le vecteur x d'origine.Cette famille possède les paramètres suivants:
- P1 = 1 − R / d
- P2 = 1 − cR / d.
L'algorithme LSH pour la recherche par plus proche voisins
L'application principale de LSH est de fournir un algorithme efficace de recherche des plus proches voisins.
L'algorithme donne une méthode de construction d'une famille LSH
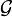 utilisable, c'est à dire telle que
utilisable, c'est à dire telle que 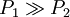 , et ceci à partir d'une famille LSH de départ. L'algorithme a deux paramètres principaux: le paramètre de largeur k et le nombre de tables de hachage L.
, et ceci à partir d'une famille LSH de départ. L'algorithme a deux paramètres principaux: le paramètre de largeur k et le nombre de tables de hachage L.- Pré-traitement
En pré-traitement, l'algorithme définit donc une nouvelle famille
de fonctions de hachage g, où chaque fonction g est obtenue par concaténation de k fonctions h1,...,hk de , i.e., g(p) = [h1(p),...,hk(p)]. En d'autres termes, une fonction de hachage aléatoire g est obtenue par concaténation de k fonctions de hachage choisies aléatoirement dans 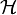 .
.L'algorithme construit ensuite L tables de hachage, correspondant chacune à une fonction de hachage g. La je table de hachage contient alors les points de
 hachés par la fonction gj. Seules les positions non-vides des tables de hachage sont conservées, en utilisant un hachage standard des valeurs de gj(p). Les tables de hachage résultats n'ont alors que n entrées (non-vides), réduisant l'espace mémoire par table à O(n) et donc O(nL) pour la structure de donnée totale.
hachés par la fonction gj. Seules les positions non-vides des tables de hachage sont conservées, en utilisant un hachage standard des valeurs de gj(p). Les tables de hachage résultats n'ont alors que n entrées (non-vides), réduisant l'espace mémoire par table à O(n) et donc O(nL) pour la structure de donnée totale.- Recherche d'un point requête q
Pour un point requête q, l'algorithme itère sur les L fonctions de hachage g. Pour chaque g considérée, on trouve les points hachés à la même position que le point requête q dans la table correspondante. Le processus s'arrête dès qu'un point r est trouvé tel que
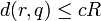 .
.Étant donné les paramètres k et L, l'algorithme a les garanties de performance suivantes:
- temps de pré-traitement: O(nLkt), où t est le temps d'évaluation d'une fonction
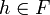 d'un point p;
d'un point p; - mémoire: O(nL)
- temps de requête:
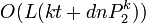 ;
; - l'algorithme a une probabilité de trouver un point à une distance cR de la requête q (si un tel point existe) avec une probabilité
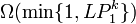 .
.
Notes et références
- ↑ (en) Gionis, P. Indyk et R. Motwani, « Similarity Search in High Dimensions via Hashing », dans Proceedings of the 25th Very Large Database (VLDB) Conference, 1999 [, texte intégral]
- ↑ a et b (en) Piotr Indyk et Rajeev Motwani, « Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality. », dans Proceedings of 30th Symposium on Theory of Computing, 1998 [, texte intégral]
- ↑ Charikar, « Similarity Estimation Techniques from Rounding Algorithms », dans Proceedings of the 34th Annual ACM Symposium on Theory of Computing 2002, 2002, p. (ACM 1–58113–495–9/02/0005)… [texte intégral lien DOI (pages consultées le 2007-12-21)]
- ↑ Jeremy Buhler, Efficient large-scale sequence comparison by locality-sensitive hashing, Bioinformatics 17: 419-428.
- ↑ (en) Alexandr Andoni et Piotr Indyk, « Near-optimal hashing algorithm for approximate nearest neighbour in high dimensions », dans Communications of the ACM, Vol. 51, 2008 [texte intégral]
- (en) Cet article est partiellement ou en totalité issu d’une traduction de l’article de Wikipédia en anglais intitulé « Locality Sensitive Hashing ».
Voir aussi
Articles connexes
Liens externes
 Portail de l’informatique
Portail de l’informatique
Catégorie : Algorithme de classification - si
Wikimedia Foundation. 2010.