- MySQL Cluster
-
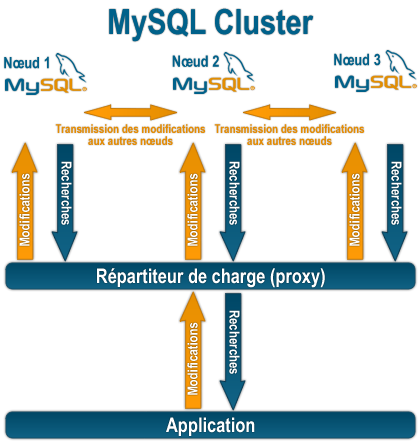
 Structure d'une grappe de serveurs MySQL.
Structure d'une grappe de serveurs MySQL.
MySQL Cluster est la base de données distribuée de MySQL. Elle permet de répartir des données sur plusieurs serveurs sans avoir de point individuel de défaillance. Contrairement aux moteurs MyISAM et InnoDB généralement utilisés avec MySQL, l'exploitation effective du cluster nécessite l'utilisation du moteur NDB, qui contient plusieurs restrictions, comme l'absence d'index FULLTEXT.
MySQL est capable, depuis la version 4.1 et grâce au moteur de stockage NDB de gérer une grappe de serveurs complète. Sa structure repose sur la duplication données, c'est-à-dire que chaque nœud fera partie d'un groupe de nœud qui posséderont tous la totalité de la base[1].
Un protocole implémenté dans chaque nœud s'occupe d'adresser chaque transaction aux différents nœuds concernés dans la grappe, il faut un minimum de 2 machines pour établir une solution de clustering MySQL et une machine (qui peut elle-même intégrer un serveur MySQL) qui va jouer le rôle de répartiteur de charge en redirigeant les requêtes sur les nœuds disponibles et les moins occupés.
Les requêtes de recherches (SELECT) seront plus rapides, mais lors d'une modification des données (une requête UPDATE, DELETE ou INSERT par exemple), celle-ci sera effectuée sur l'ensemble des nœuds, ce qui bloquera l'ensemble grappe pendant cette opération.
Par rapport à un système de réplication, la redondance est améliorée : si un nœud tombe en panne, sa charge est automatiquement reprise par les autres nœuds.
L'ajout d'un nouveau nœud peut se faire sans avoir besoin de repartitionner la base, il suffit de le faire reconnaître par la grappe et le redémarrage d'un nœud peut se faire sans avoir à redémarrer la grappe.
Du point de vue de MySQL, chaque nœud fait partie d'un ensemble qui pourrait être reconnue comme une seule machine. Pour le programmeur, il doit programmer son application pour communiquer avec le répartiteur de charge.
Cette solution s'adapte parfaitement lorsque la disponibilité et la sécurité des données est un problème critique et que l'on recherche un partitionnement technique responsable de l'écriture. Couplé a des fonctionnalités temps réel et a une API de programmation asynchrone NDB Cluster s'adresse principalement aux exigences du marché des télécommunications.
Sommaire
Architecture
MySQL Cluster a plusieurs concepts importants derrière sa conception.
Réplication
MySQL Cluster utilise la réplication synchrone par un méchanisme de two-phase commit pour garantir que la donnée est copiée sur plusieurs serveurs lors du commit (validation). Ceci contraste avec ce qui est généralement effectué avec la Réplication MySQL Master/Slave, qui est asynchrone[2]. Deux copies, appelées répliques, des données sont requises pour garantir la disponibilité. Toutefois, le cluster peut être configuré pour stocker une ou plusieurs copies simultanément.
Depuis MySQL 5.1, il est également possible de mettre en place une réplication asynchrone entre plusieurs clusters. Cette technique est généralement appelée MySQL Cluster Replication ou Réplication géographique[3].
Horizontal Data Partitioning
Les données des tables NDB sont automatiquement partitionnées sur l'ensemble des nœuds de données du système. Ceci est effectué par un algorithme de hashage basé sur la clef primaire de la table et est transparente pour l'application qui l'utilise.
Depuis la version 5.1, les utilisateurs peuvent définir leurs propres schémas de partitionnement.
Stockage hybride
MySQL Cluster peut stocker les données soit en mémoire, soit sur le disque. Toutes les données et les index peuvent être stockées en mémoire, en écrivant les données sur le disque de manière asynchrone. La réplication décrite ci-dessus permet d'effectuer cette transaction de manière sûre.
Pas de point unique de défaillance
MySQL Cluster est conçue de manière à n'avoir aucun point unique de défaillance. En supposant que le cluster soit configuré correctement, chaque nœud, système ou partie matérielle peut tomber en panne sans altérer la disponibilité du cluster. Les disques partagés ne sont pas nécessaires. Les connexions entre les nœuds peuvent s'effectuer par le standard Ethernet.
Implémentation
MySQL Cluster utilise trois différents types de nœuds :
- Data node (processus ndbd) : ces nœuds contiennent les données des tables NDB.
- Management node (processus ndb_mgmd) : utilisé pour la configuration et la supervision du cluster. Ils ne sont nécessaires que pour le démarrage d'un autre nœud (Data node ou SQL node).
- SQL node (processus mysqld) : Un serveur MySQL tel qu'utilisé sur un serveur MySQL classique. Il se connecte aux Data nodes pour le stockage et la lecture des données.
Voir aussi
Notes et références
Une partie de cet article a été traduit depuis en:MySQL Cluster.
Wikimedia Foundation. 2010.