- Workload Management
-
Workload Manager
Dans le domaine des systèmes d'exploitation pour ordinateurs, le Workload Management est un terme qui provient de l'anglais, et qui désigne un ensemble de techniques destinées à optimiser la charge de la machine et du réseau.
Le Workload Manager est le logiciel ou composant du système d'exploitation qui met en œuvre ces techniques.
Le premier workload manager connu est celui inclus dans le système d'exploitation MVS/ESA paru en 1994[1], et utilisé sur les mainframes d'IBM. Depuis, des logiciels utilisant les techniques du workload management sont parus pour d'autres matériels et systèmes d'exploitation. Par exemple :
- AIX Workload Manager
- HP-UX Workload Manager
- Solaris Resource Manager
- Sous Linux, le projet Class-based Kernel Resource Management (CKRM).
En informatique distribuée, le projet gLite[2] est un middleware (intergiciel) pour grille informatique, qui utilise un "Workload Management System" afin de partager les ressources des ordinateurs entre les programmes utilisant la grille.
Sommaire
Principes du workload management
Problématique
Pour des raisons de coût, les utilisateurs de gros systèmes informatiques essayent de maximiser l'utilisation des ressources de la machine [3].
Mais lorsque l'utilisation d'une ressource se rapproche de 100%, la longueur de la file d'attente pour cette ressource tend vers l'infini, selon la formule[4] :
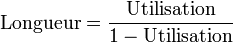 .
.En conséquence, le temps d'attente pour accéder à ladite ressource augmente aussi[5]. Par exemple, considérons un processeur utilisé à 99%, et que chaque processus l'utilise durant 1 centième de seconde. Selon la formule évoquée plus haut, en moyenne 99 processus sont en attente, et le temps d'attente moyen est donc de 0,99 secondes. Donc la réactivité du système s'en ressent, puisqu'il va s'écouler environ une seconde avant qu'un processus entrant dans le système ne soit servi[6].
Il y a donc un compromis à effectuer entre une utilisation élevée des ressources et des temps d'attente acceptables pour les applications.
L'utilisation de techniques évoluées d'ordonnancement, telles que CFS, ne permet pas de résoudre complètement ce problème. Pour cela, le workload management propose une autre approche que celle des ordonnanceurs classiques.
Algorithme
L'administrateur du système définit à l'avance des service classes (abr. SC, trad. litt. : classes de service). Ces classes regroupent des ensembles d'applications ou de transactions, qui peuvent être définies par leur nom, celui de l'utilisateur ou du groupe qui les exécute.
Pour chacune de ces classes, l'administrateur définit une importance (du plus prioritaire au moins prioritaire) et des objectifs.
Les objectifs à atteindre sont spécifiés sous forme de :
- Temps de réponse moyen
- Par exemple : 10 s. de temps de réponse moyen pour une requête de BDD en SQL.
- Temps de réponse par pourcentages
- Par exemple : 90% des requêtes Web répondues en moins de 1 s.
- Vélocité d'exécution (en anglais execution velocity) moyenne
- Par exemple : utilise les ressources du processeur en moyenne 10% du temps.
À l'aide de ces informations, le workload manager effectue à intervalles réguliers les actions suivantes :
- Il mesure en permanence les performances et temps de réponse de chaque application et chaque transaction.
- Avec ces mesures, il calcule un index de performances (Performance Index, PI) pour chaque service class.
- Le workload manager décide alors quelles classes peuvent libérer des ressources (processeur, mémoire, entrées/sorties), et quelles classes en ont besoin : ces classes sont appelées respectivement donneurs et receveurs.
- Le workload manager essaie de prédire l'effet du transfert de ressources d'un donneur à un receveur. Si l'effet prédit est (globalement) positif, le transfert pourra être retenu.
- Le workload manager applique ces transferts.
- Au cycle suivant, le workload manager compare le PI obtenu avec la prédiction, et ajuste éventuellement ses prédictions (par exemple si un transfert n'a pas eu l'effet souhaité).
La méthode la plus simple pour établir la liste des receveurs potentiels est de parcourir les importances, de la plus haute à la plus basse, et d'y inscrire les classes avec une mauvaise performance (mauvais PI) : ce sont en effet les tâches qui ne remplissent pas leurs objectifs.
Pour la liste des donneurs potentiels, on procède en sens inverse : on part de la plus basse importance, avec les classes qui ont un bon PI. Au cas où aucune classe n'a de bon PI (le système est alors surchargé), on sélectionne comme donneurs les classes en partant de l'importance la plus basse : le workload manager décide délibérément de diminuer les ressources des tâches les moins importantes pour les allouer aux tâches les plus importantes.
Par rapport à un ordonnanceur classique, un workload manager a donc l'avantage de connaitre à l'avance quelles tâches il peut favoriser ou défavoriser en priorité, et à utilisation égale, la réactivité perçue sera meilleure[7].
L'inconvénient principal d'un workload manager est le travail nécessaire pour classifier tous les utilisateurs, applications et transactions. Autre inconvénient : un workload manager consomme plus de ressources système qu'un ordonnanceur classique.
Un exemple d'implémentation
Pour les mainframes d'IBM, le Workload Manager (abr. WLM) est l'un des composants de base du système d'exploitation MVS et de ses successeurs, z/OS inclus. La première version de WLM est sortie en 1994 avec MVS/ESA version 5.1.0[8]. WLM gère l'accès aux ressources système sur la base d'objectifs prédéfinis par l'administrateur.
Sur un mainframe, plusieurs applications sont exécutées en même temps. Ces travaux nécessitent des temps d'exécution stables, ainsi que des temps d'accès prévisibles aux bases de données. Le mécanisme de classification des travaux en service classes utilise des attributs comme le nom des transactions, l'identification de l'utilisateur ou le nom des programmes utilisés par des applications spécifiques.
Sous z/OS, l'importance d'une classe est définie par un nombre de 1 (le plus important) à 5 (le moins important). L'importance 6 est utilisée pour désigner les tâches discrétionnaires, qui ne s'exécutent qu'en dernier lieu, typiquement les travaux en batch.
Sous z/OS, le temps de réponse d'une requête est la durée écoulée entre l'entrée de cette requête dans le système et le signal de fin de traitement par l'application. Pour ce faire, il faut que le code de l'application soit adapté, ce qui peut poser des problèmes dans le cas d'anciennes applications qui ne peuvent plus être modifiées[9].
Dans ce cas, une autre mesure, celle de la vélocité d'exécution (execution velocity) reste possible. Elle se base sur la mesure régulière des états du système, qui décrivent quand une application utilise une ressource, et quand elle doit attendre, dans le cas où cette ressource est déjà utilisée. WLM mesure le nombre d'échantillons représentant des états d'attente et des états d'utilisation pour chaque ressource utilisée par la service class. La vélocité (en pourcentage) est alors le quotient du nombre d'échantillons d'attente par la somme des échantillons :
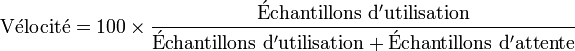
Cette mesure ne nécessite aucune communication entre l'application et WLM, mais est plus abstraite qu'un objectif en temps de réponse.
L'administrateur système assigne une importance à chaque service class pour décrire à WLM laquelle devrait avoir accès en priorité aux ressources systèmes, si la charge machine est trop importante pour que tous les travaux puissent être exécutés simultanément.
Sous z/OS, les service classes peuvent être subdivisées en périodes. Une tâche qui démarre commence dans la première période, et tente d'atteindre les objectifs de cette période. Pendant ce temps, WLM mesure les ressources consommées par cette tâche, et au cas où elles dépassent un seuil prédéfini par l'administrateur (par exemple 5 secondes de temps CPU pour une requête de BDD plus complexe que la moyenne), WLM fait basculer la tâche dans la période suivante, qui a alors des objectifs moins ambitieux. Cette méthode évite d'allouer un maximum de ressources à des tâches qui ne pourraient en aucun cas atteindre les objectifs initiaux.
Les service classes et définitions d'objectifs, ainsi que d'autres structures de reporting et de contrôle, sont rassemblées dans des service policies, et sauvegardées dans des service definitions. La définition qui a été activée est aussi sauvegardée dans un Couple Data Set sur la Coupling Facility, ce qui permet à tous les systèmes z/OS au sein d'un cluster Parallel Sysplex de la partager et de fonctionner avec les mêmes objectifs de performance[10].
Sous z/OS, l'index de performance (PI) est calculé suivant les formules :
Les données utilisées pour ce calcul sont agrégées sur un intervalle pouvant aller des 20 dernières secondes aux 20 dernières minutes, afin d'obtenir un résultat statistiquement fiable. Lors de chaque intervalle de décision, WLM n'exécute de transfert que pour le bénéfice d'une seule service class, afin de conserver la maîtrise et la prévisibilité du système.
WLM gère les accès des différents travaux aux processeurs, aux unités d'entrée/sortie, à la mémoire, et il démarre et arrête les processus pour l'exécution des travaux. Par exemple l'accès aux processeurs est géré par des dispatch priorities (litt. priorités d'exécution), qui définissent un classement relatif entre les unités de travail à exécuter. Une dispatch priority commune est assignée à toutes les unités de travail qui sont classées dans la même service class. La dispatch priority n'est pas fixe[11], et n'est pas une simple dérivée de l'importance de la service class. Elle change en fonction des objectifs atteints, de l'utilisation du système, et de la demande de travail pour les processeurs. Des mécanismes similaires permettent à WLM de gérer l'accès aux autres ressources : d'une manière générale, WLM assigne des priorités dans les différents type de queues pour les ressources du système.
Ce fonctionnement de WLM est désigné sous le terme de goal-oriented workload management, littéralement workload management orienté objectifs, et contraste avec le workload management orienté ressources, et qui définit une relation plus statique pour l'accès des ressources par les travaux.
Une différence fondamentale avec les logiciels de workload management sur d'autres systèmes d'exploitation est la coopération étroite entre celui de z/OS et les applications majeures, telles que le middleware ou les sous-systèmes qui s'exécutent sous z/OS[12]. WLM propose des interfaces qui permettent aux sous-systèmes de communiquer à WLM le début et la fin d'une unité de travail dans le système, ainsi que des attributs de classification, qui peuvent être utilisés par l'administrateur pour classer le travail sur le système. De plus, WLM propose aussi des interfaces qui permettent aux composants de répartition de charge de travail de positionner les requêtes sur les meilleurs systèmes à l'intérieur d'un cluster Parallel Sysplex, par exemple pour orienter une requête DRDA vers le serveur ayant le plus de capacité disponible.
Des mécanismes supplémentaires aident les gestionnaires de ressources ou de base de données à signaler les situations de blocage à WLM, afin que ce dernier accélère les travaux retardés en favorisant les processus à l'origine dudit blocage.
Au fil du temps, WLM est devenu le composant central pour tous les aspects liés à la performance au sein du système d'exploitation z/OS. Dans un cluster Parallel Sysplex, les composants WLM de chaque système travaillent ensemble pour fournir une vision unifiée pour les applications exécutées dans le cluster. Sur un System z avec des partitions virtuelles multiples, WLM permet d'interagir avec le LPAR Hypervisor pour influencer le poids des partitions z/OS, et de gérer la part de temps processeur pouvant être consommée par chaque partition logique.
Références
- ↑ cf. MVS/ESA 5.1.0 Technical Presentation Guide
- ↑ voir les liens externes. gLite est distribué sous licence libre (Apache)
- ↑ cf. Redbook System Programmer's Guide to: Workload Manager
- ↑ en application de la loi de Little
- ↑ proportionnellement à la longueur de la file d'attente
- ↑ cf. Systèmes d'exploitations de Tanenbaum pour une discussion sur les problèmes causés par le multi-tâches et le partage des ressources. Voir aussi la page Système d'exploitation.
- ↑ d'après le System Programmer's Guide to: Workload Manager
- ↑ cf. MVS/ESA 5.1.0 Technical Presentation Guide
- ↑ pour répondre à cette problématique, z/OS propose aussi l'ajout de Performance Blocks
- ↑ pour des explications sur les termes Coupling Facility, Parallel Sysplex, etc., voir LPAR et Parallel Sysplex (en)
- ↑ sauf pour les travaux du système d'exploitation qui sont dans les service classes fixes SYSTEM et SYSSTC
- ↑ d'après le System Programmer's Guide to: Workload Manager
Bibliographie
- Andrew Tanenbaum (2003) Systèmes d’exploitation, 2e éd., Pearson Education France, ISBN 2-7440-7002-5
- (en) Pierre Cassier et al. (2008) System Programmer's Guide to: Workload Manager, 4e éd., IBM Redbook SG24-6472.
- (en) Sofia Castro et al. AIX 5L Workload Manager (WLM). IBM Redbook SG24-5977
- (en) IBM : MVS/ESA 5.1.0 Technical Presentation Guide. IBM Redbook GG24-4137-00
- (en) IBM : MVS Planning Workload Management. SA22-7602-16
- (en) HP : HP-UX Workload Manager User’s Guide. B8844-90014
Voir aussi
- Cet article est issu d'une traduction totale ou partielle de l'article Wikipedia en anglais : (en) en:Workload Manager.
- Théorie des files d'attente
- Ordonnancement dans les systèmes d'exploitation
- Théorie de l'ordonnancement
- Completely Fair Scheduler
- Système d'exploitation
Liens externes
- (en) z/OS WLM Homepage : http://www.ibm.com/servers/eserver/zseries/zos/wlm/
- (en) "Workload Management Overview"
- (en) Solaris Resource Manager : http://www.sun.com/software/resourcemgr/
- (en) Projet CKRM : http://ckrm.sourceforge.net/
- (en) "Advanced Workload Management Support for Linux" : http://ckrm.sourceforge.net/downloads/ckrm-linuxtag04-paper.pdf
- (en) Projet gLite : http://glite.web.cern.ch/glite/
Catégories : Algorithme d'ordonnancement | Grands Systèmes
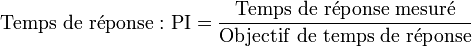
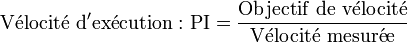
Wikimedia Foundation. 2010.