- Réplication (informatique)
-
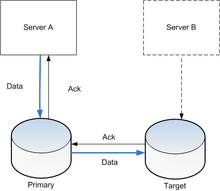 Réplication de données
Réplication de données
En cas d'indisponibilité du stocakge primaire ou du site primaire, le serveur B peut accéder à la réplication des donnéesEn informatique, la réplication est un processus de partage d'informations pour assurer la cohérence de données entre plusieurs sources de données redondantes, pour améliorer la fiabilité, la tolérance aux pannes, ou l'accessibilité. On parle de réplication de données si les mêmes données sont dupliquées sur plusieurs périphériques.
La réplication n'est pas à confondre avec une sauvegarde : les données sauvegardées ne changent pas dans le temps, reflétant un état fixe des données, tandis que les données répliquées évoluent sans cesse à mesure que les données sources changent.
Sommaire
Réplication active/passive
On distingue couramment la réplication passive et active. Lors de réplication active, les calculs effectués par la source (ou maître) sont répliquées, alors que lors de réplication passive, seul le serveur maître procède au calcul et il ne propage que les modifications finales de la mémoire à effectuer.
Si à tout moment un unique maître est désigné pour effectuer toutes les requêtes, on parle d'un schéma primaire (schéma maître-esclave) : c'est souvent l'architecture employée pour des clusters de serveurs à haute disponibilité.
Si par contre, n'importe quel serveur peut traiter une requête, on parle de schéma multi-maître (multi-master replication). Cette architecture pose des problèmes de contrôle de concurrence : plusieurs processus qui travailleraient de manière incontrôlée sur les mêmes données pourraient remettre en cause la cohérence globale du système.
En base de données
Dans une base de données, la réplication est fréquemment utilisée pour des systèmes qui ont à soutenir une forte charge : le serveur maître journalise les opérations effectuées, et les esclaves, à partir de ce journal, dupliquent les opérations effectuées. Ainsi, moyennant un petit temps de retard (replication lag), les mêmes données sont disponibles sur plusieurs serveurs en même temps, ce qui permet un processus de répartition de charge.
La plupart des systèmes de gestion de base de données modernes permettent un schéma multi-maître : cependant, celui-ci introduit de nombreux coûts supplémentaires. La résolution, ou la prévention de conflits entre plusieurs transactions simultanées est par exemple très complexe.
Réplication au niveau disque
La réplication de disque peut être utilisée pour dupliquer les mise à jour au niveau bloc de données sur plusieurs espaces de stockage. De cette façon le système de fichiers supportant le système d'exploitation peut être sécurisé, soit en local (RAID logique ou physique) soit à distance. La réplication distante (entre deux systèmes ou entre deux espaces de stockage) peut elle même être réalisée de façon synchrone[1] (les deux espaces sont a tout moment identiques au bloc près) soit asynchrone[2] (il peut y avoir un léger décalage de la mise à jour de la cible distante, l'entrée/sortie étant considérée comme terminée dès l'acquittement au niveau de l'espace de stockage primaire.
Systèmes de réplication
- DRBD module (Linux).
- EMC SRDF
- IBM PPRC and Global Mirror (IBM Copy Services)
- Hitachi TrueCopy
- Hewlett-Packard Continuous Access (HP CA)
- Symantec Veritas Volume Replicator (VVR)
- DataCore SANsymphony & SANmelody
- FalconStor Replication & Mirroring (sub-block heterogeneous point-in-time, async, sync)
- Compellent Remote Instant Replay
- EMC RecoverPoint
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Replication (computer science) » (voir la liste des auteurs)
Wikimedia Foundation. 2010.