- ReCaptcha
-
reCAPTCHA
 Logo du reCAPTCHA.
Logo du reCAPTCHA.
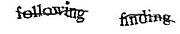 Un exemple de reCAPTCHA : les mots à reconnaître sont « following » et « finding ».
Un exemple de reCAPTCHA : les mots à reconnaître sont « following » et « finding ».reCAPTCHA est un système mettant à profit les capacités de reconnaissance des utilisateurs humains mobilisées par les tests Captcha, pour améliorer par la même occasion le processus de numérisation de livres, là où échouent les systèmes de reconnaissance optique de caractères (OCR). Le système a été mis au point par des chercheurs de l'Université Carnegie-Mellon[1],[2].
Sommaire
Description
L'idée est de rendre utile une tâche qui peut sembler rébarbative. La technique tient du crowdsourcing.
Concrètement, par rapport à un processus habituel d'authentification par Captcha, ce ne sont pas un mais deux mots qui sont présentés à l'utilisateur. L'un d'eux est un Captcha habituel, dont la solution est par conséquent connue de manière certaine ; seul l'autre est issu de la numérisation d'un livre : c'est celui dont la solution est incertaine voire inconnue et que l'utilisateur va aider à résoudre.
Le système part du principe que si les utilisateurs résolvent correctement le Captcha habituel, alors ils ont aussi déchiffré correctement le mot inconnu. Néanmoins, un mot n'est considéré comme vraiment reconnu que si plusieurs utilisateurs l'ont vérifié en obtenant le même résultat.
Les mots à reconnaître sont issus de numérisations opérées par Internet Archive sur des ouvrages anciens appartenant au domaine public. Ils sont fournis lors des requêtes par le site Web du projet reCAPTCHA[3], issu du projet CAPTCHA originel, tous deux mis en place par l'école d'informatique de l'Université Carnegie Mellon, dans la ville américaine de Pittsburgh. Ceci est réalisé au moyen d'une API écrite en JavaScript, dans laquelle le serveur rappelle reCAPTCHA après que la requête a été soumise. Le projet reCAPTCHA propose des bibliothèques pour différents langages de programmation afin de faciliter le processus. Le service est gratuit, à l'exception des utilisateurs qui auraient besoin d'une bande passante trop élevée.
Le but de reCAPTCHA est le même que celui poursuivi par Distributed Proofreaders, un autre projet visant également à valider l'OCR par des opérateurs humains, mais de manière conventionnelle, sans avoir recours aux Captchas.
Histoire
En 2009, le projet reCAPTCHA est à même de numériser les archives du New York Times[4]. En date de septembre 2009, environ 20 ans d'archives ont été numérisés et les responsables du projet espèrent avoir complètement numérisé les 110 autres années avant la fin de 2010. [5] Le 17 Septembre 2009, Google annonce l'acquisition de la société ReCAPTCHA. Celle-ci sera notamment utilisée dans le processus de numérisation d'ouvrage Google Books.
Notes et références
- ↑ (en) Luis von Ahn, Ben Maurer, Colin McMillen, David Abraham and Manuel Blum, « reCAPTCHA: Human-Based Character Recognition via Web Security Measures », dans Science, vol. 321, 2008, p. 1465-1468 [[pdf] texte intégral lien DOI]
- ↑ (en) The reCAPTCHA project, partie du Carnegie Mellon School of Computer Science de l'Université Carnegie-Mellon
- ↑ (en) recaptcha.net, site du projet reCAPTCHA.
- ↑ (en) Learn more, reCAPTCHA.net. Consulté le 2008-11-23
- ↑ (en) Luis von Ahn. NOVA ScienceNow s04e01 [Television production]. Retrieved on 2009-07-06. Scene occurs at 46:58. “The New York Times has this huge archive, over 130 years of newspaper archive there. And we've done maybe about 20 years so far of The New York Times in the last few months and I believe we're going to be done next year by just having people do a word at a time.”
Voir aussi
Articles connexes
 Portail de la sécurité informatique
Portail de la sécurité informatique
Catégories : Vision artificielle | Technologie web | Sécurité informatique | Spam | Sigle de 9 caractères ou plus

Wikimedia Foundation. 2010.