- O/c
-
Surfréquençage
Le Surfréquençage, ou Overclocking en anglais, également nommé surcadencement (puisqu'on parle de machine cadencée à x, y GHz), a pour but d'augmenter la fréquence de travail (mesurée en Hz) d'un processeur.
Cette opération n'est pas risquée tant que le surfréquençage reste raisonnable et que certaines précautions sont prises :
- contrôle de la température du processeur à l'aide d'un logiciel, et augmentation du refroidissement,
- si nécessaire, augmentation de la tension du processeur et de la mémoire (VCore). Cette opération n'est nécessaire que si des problèmes de stabilité surviennent pendant l'utilisation. Elle est même nécessaire pour atteindre des haute fréquences. Naturellement, en fonction du modèle du processeur il ne faudra pas dépasser un certain seuil.
- contrôle de la qualité de la mémoire vive. Certaines mémoires (RAM) ne supporteront tout simplement pas ou très peu le surfréquençage, surtout quant il s'agit de barrettes de qualité médiocre ou sans-marque combiné à un processeur puissant.
Le principe du surfréquençage est simplement de faire fonctionner des composants électroniques (notamment microprocesseurs ou cartes graphiques) à une fréquence d'horloge supérieure à celle pour laquelle ils ont été conçus et/ou validés.
Sommaire
But recherché
Le but est d'obtenir des performances supérieures à moindre coût, en poussant un composant à des limites supérieures à ses spécifications techniques. On s'y livrera d'autant plus volontiers qu'on s'estime prêt à changer de machine si l'ancienne ne peut être amenée aux performances souhaitées et qu'on est prêt à la "griller" par fausse manipulation ou vieillissement prématuré du microprocesseur.
Cette pratique est très répandue parmi les utilisateurs avertis d'ordinateurs. Elle concerne en général le microprocesseur central (CPU) et/ou le processeur graphique, mais concerne egalement d'autres composants, tel que la mémoire (qui accompagne l'overclocking du microprocesseur, puisque la fréquence mémoire est directement lié a la fréquence du microprocesseur).
Inversement, le sous-cadencement (ou Underclocking) est une technique utilisée pour réduire considérablement le bruit ou la consommation électrique d'une machine. La même machine peut fort bien être volontairement surcadencée pour les jeux et sous-cadencée pour les travaux d'Internet et de bureautique. Des bases de données disponibles sur la Toile consolident les expériences individuelles dans ce domaine. Cette pratique est de plus en plus repandu chez les constructeurs, proposant par exemple des modes turbo ou eco, agissant directement sur le coefficient multiplicateur qui se répercute donc sur la fréquence de fonctionnement du microprocesseur. Ce changement de coefficient peut etre statique ou dynamique, c'est à dire, changeant automatiquement en fonction de la demande en ressources.
Risques
Un surcadencement mal réalisé peut altérer le fonctionnement du matériel de manière plus ou moins grave, allant d'une simple surchauffe du composant surcadencé (il perd alors en stabilité) à la destruction d'un ou plusieurs éléments de la configuration. Les constructeurs configurent toujours leurs ordinateurs à des fréquences moindres que les fréquences limites (afin de se laisser une marge de sécurité évitant un trop grand nombre de retours sous garantie), ce qui permet une marge de surcadencement.
Pour pallier l'augmentation de température provenant des composants surcadencés, l'utilisation de système de refroidissement à air avec ou sans caloducs et/ou de système de refroidissement à eau (watercooling) est préconisée. Dans la pratique extrême de cette discipline, les spécialistes utilisent des refroidissements à l'azote liquide (-196°C) et/ou des refroidissement à changement de phase (Montage simple étage: Direct on die ou Montage multi-étages: cascade).
Le surcadencement ne nuit pas à la stabilité du processeur si l'on reste dans des fréquences supportables par les composants. Il est souvent nécessaire de modifier légèrement les tensions de fonctionnement pour aider le processeur à « tenir » la nouvelle cadence sans instabilité.
Le bruit des ventilateurs devenant peu acceptable pour les applications gourmandes, on recourt parfois à l'ajustement inverse (le sous-cadencement ou underclocking) afin de diminuer les besoins en dissipation thermique, et donc permettre le sous-voltage du ventilateur de refroidissement, ou le passage en refroidissement passif, pour diminuer le bruit.
Théorie du surfréquençage
Cette technique répond à la demande des micro-ordinateurs modernes qui doivent faire face à des programmes de plus en plus gourmands. Elle cherche à obtenir la puissance maximale à partir d'une configuration existante. On peut l'insérer dans une recherche plus générale de la performance des systèmes informatiques.
Le nombre de cycles par instruction
La plupart des ordinateurs fonctionnent de manière synchronisée en utilisant un signal d'horloge CPU à fréquence constante (la fréquence d'horloge, exprimée en hertz, égale l'inverse de la période - durée d'un cycle d'horloge - exprimée en secondes).
Une instruction d'ordinateur est un ensemble d'opérations élémentaires ou micro-instructions dont le nombre et la complexité dépendent de l'instruction, de l'organisation et de l'implémentation exacte dans le CPU. Une micro-opération est une opération matérielle élémentaire qui peut être exécutée en un cycle d'horloge. Cela correspond à une micro-instruction dans un CPU micro-programmé. Par exemple, les opérations sur les registres, les décalages, les chargements, les incréments, les opérations de l'unité arithmétique et logique : addition, soustraction, etc.
Cependant une instruction machine peut prendre un ou plusieurs cycles pour être entièrement traitée ; c'est le nombre de cycles par instruction ou, en anglais, cycles per instruction (CPI).
Une instruction-machine = 1 ou N micro instructions = 1 ou N CPI.
Voici un extrait de la documentation fournie aux développeurs de compilateurs ou de programmes. On peut y voir une liste d'instructions du micro-processeur AMD A64 avec leur nombre de cycles. AMD définit les latences de ces instructions comme suit : La colonne des latences fournit les attentes pour une exécution statique de l'instruction. L'exécution statique est le nombre de cycles que prend le traitement séquentiel, jusqu'à son terme, des micro-opérations composant l'instruction. Ces valeurs sont à titre indicatif. On suppose que
- L'instruction est immédiatement disponible dans le cache L1 et que l'opération peut être exécutée avec les autres opérations du planificateur de tâches.
- Les opérandes sont disponibles dans le cache L1
- Il n'y pas de contention avec les autres ressources.
Les deux instructions suivantes :
- Call pntr16 16/32, qui correspond à un appel à une routine et qui dure 150 cycles,
- CLC, qui correspond à un effacement de registre et qui dure 1 cycle,
montrent l'étendue que peut avoir le CPI pour des instructions différentes. Cette documentation est disponible chez AMD sous le titre software optimization guide for AMD Athlon 64 and AMD Opteron processors.
Le temps d'exécution d'un programme
Pour un programme compilé donné qui s'exécute sur une machine donnée A, les paramètres suivants sont fournis :
- Le nombre moyen de CPI
- Le nombre total d'instructions du programme
- La période de l'horloge ou durée d'un cycle de la machine A.
Comment peut-on mesurer la performance de cette machine exécutant ce programme ? Intuitivement, la machine est réputée rapide ou meilleure en exécutant ce programme si le temps total d'exécution est court. Cependant, l'inverse de ce temps total d'exécution est une mesure métrique possible ou mesurable : Performance (A) = 1 / temps total d'exécution de la machine A.
Comparer les performances en utilisant le temps total d'exécution
Pour comparer les performances de deux machines A et B exécutant un programme donné :
- Performance (A) = 1 / temps total d'exécution de la machine A
- Performance (B) = 1 / temps total d'exécution de la machine B.
La machine A est n fois plus rapide que la machine B signifie :
n = Performance (A) / Performance (B) = (temps total d'exécution de la machine A) / (temps total d'exécution de la machine B).
Par exemple, pour un programme donné :
- temps total d'exécution de la machine A = 1 seconde
- temps total d'exécution de la machine B = 10 secondes
Performance (A) / Performance (B)= 10 / 1 = 10
La performance de la machine A est 10 fois la performance de la machine B quand elle exécute ce programme ; la machine A est dite 10 fois plus rapide que la machine B. Le temps total d'exécution. L'équation du CPU.
Un programme est une ensemble d'instructions,I, mesuré en instruction / programme. L'instruction moyenne donne un nombre de cycle moyen par instruction mesuré en cycle / instruction ou CPI. Le CPU a une fréquence d'horloge fixe dont la période C = 1/ fréquence d'horloge mesuré en second / cycle.
Le temps d'exécution du CPU est le produit de ces trois paramètres tel que : Le Temp CPU = le nombre de seconde / programme = instruction / programme * en cycle / instruction * second / cycle
T = I * CPI *C
Par exemple, pour un programme s'exécutant sur une machine donnée avec les paramètres suivants : L'ensemble d'instruction du programme : 10 000 000 instructions un nombre de cycle moyen par instruction : 2.5 cycles / instruction Fréquence d'horloge du CPU : 200 Mhz. = 1/ 5* 10 e -9
Quel est le temps d'exécution pour ce programme ?
Le Temps CPU = instruction / programme * en cycle / instruction * seconde / cycle
Le Temps CPU = instruction / programme * en cycle / instruction * seconde / cycle = 10 00 00 * 2.5 * 5 * 10 e -9 = .125 secondes.
En conclusion, en augmentant la fréquence du CPU, donc en diminuant la durée d'un cycle, on diminue la durée d'exécution d'un programme. La fréquence n'est pas la puissance
L'overclocking suffit-il à garantir une machine plus rapide ? La fréquence est-elle la puissance ? Les facteurs affectant les performances du CPU sont les facteurs affectant le temps d'exécution.
Le Temps CPU = instruction / programme * en cycle / instruction * seconde / cycle ce qui donne T = I * CPI *C
Dans ce tableau, les facteurs affectant I,CPI,C
- I est affecté par le programme,compilateur et l'architecture
- CPI est affecté par le jeu d'instruction du CPU et l'architecture
- C ou la fréquence est affectée par le jeu d'instruction du CPU,l',architecture et la technologie
Performance comparée de deux CPU sur le même programme.
L'architecture du CPU est le facteur le plus important pour le CPI, il détermine le CPI. Une classe d'instructions est un ensemble d'instructions ayant le même CPI. La machine A possède le jeu d'instructions réparti dans ces trois classes tel que:
(Classe d'instruction,CPI) (A,1), (B,2), (C,3)
La machine B possède le jeu d'instruction réparti dans ces trois classes tel que :
(Classe d'instruction, CPI) (A,2), (B,2) (C,3)
La machine A possède des registres de 64 bits et la machine B de 32 bits. Les mêmes opérations utilisant la classe A nécessitent par exemple le double d'accès de la part de la machine B en utilisant sa propre classe A.
- La machine A prend C(A) secondes par cycle soit une fréquence de F(A) = 1/C(A).
- La machine B prend C(B) secondes par cycle soit une fréquence de F(B) = 1/C(B).
Après compilation c'est-à-dire après la traduction du programme à partir des jeux d'instructions respectifs des machines A et B on obtient par exemple: Programme compilé pour la machine A
(Classe d'instructions,nombre d'instructions) (A,5), (B,1), (C,1)
Programme compilé pour la machine B
Classe d'instruction,nombre d'instructions) (A,5), (B,1), (C,1)
Les compilateurs pour la machine A et B génèrent ici le même nombre d'instructions par classe. Il s'agit d'un P4 et d'un AMD 64 qui utilisent pour notre exemple les mêmes jeux d'instructions pour notre exemple (SSE2, MMX, SSE3, etc ).
Le nombre de cycles nécessaire à l'exécution du programme sur la machine A est N(A) qui vaut : 5*1 + 1*2+1*3 = 10 millions de cycles.
Le nombre de cycles nécessaire à l'exécution du programme sur la machine B est N(B) qui vaut : 5*2 + 1*2+1*3 = 15 millions de cycles.
- Pour que la machine A soit aussi rapide que la machine B il faut que les temps d'exécution de la machine A et de la machine B pour ce programme soit égaux donc :
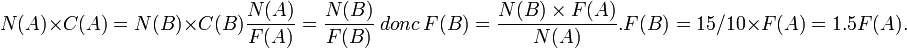
La machine B sera aussi rapide que la machine A POUR CE PROGRAMME si sa fréquence d'horloge est 1.5 fois plus rapide.
L'overclocking améliore donc les performances d'une machine mais les choix architecturaux tel que le type de processeur ont plus d'impact. Le surfréquençage et la loi de G. Amdahl
Voici quelques exemples d'améliorations du traitement d'un programme par l'optimisation de l'affectation des ressources, améliorer les accès mémoires, surfréquençage inutile du CPU sur un programme de gestion de bases de données. Nous utiliserons les recherches de G Amdahl en très simplifiées pour justifier notre démarche d'un point de vue théorique. Référence bibliographique Gene Amdahl, Validity of the Single Processor Approach to Achieving Large-Scale Computing Capabilities, AFIPS Conference Proceedings, (50), pp 483-485, 1967. Il est un des pères des architectures des mainframes IBM, Amdahl, Hitachi.
L'augmentation des performances possibles par une amélioration de la conception est limitée par l'utilisation totale de cette amélioration. Autrement dit, une amélioration non utilisée n'améliore pas les performances.
L'accélération A de l'exécution d'un programme A est égale au Temps d'exécution sans A / Temps d'exécution avec A.
C'est la loi d'Amdahl. Supposons que cette accélération A affecte une fraction F du temps d'exécution du programme par un facteur S et que le reste du temps ne soit pas affecté. Le temps d'exécution avec A =((1-f)+f/s) * temps d'exécution sans A
A = Temps d'exécution sans A / Temps d'exécution avec A A = Temps d'exécution sans A / (((1-f)+f/s) * temps d'exécution sans A) A =1 / ((1-f)+f/s)
Par exemple . Si nous avons les classes d'instructions suivantes pour un CPU donné.
(Classe d'instruction,CPI),(A,3)(B,4)(C,5)
La classe A représente des instructions de l'ALU qui n'accèdent pas à la mémoire. La classe B représente des instructions d'accès à la mémoire, lecture écriture. La classe C représente des instructions de branchement.
Si nous avons pour chaque classe la fréquence d'utilisation des ces instructions dans un programme donné:
(Classe d'instruction,fréquence d'utilisation) (A,10%),(B,20%),(C,70%)
Chaque classe représente un % du temps d'exécution total de ce programme : Fréquence d'utilisation * CPI / somme (des fréquences de chaque classe * CPI de chaque classe) 0.3 + 0.8 + 3.5 = 4.6 est le CPI du programme de durée 100.
Classe d'instructions
- A : 0.10 * 3 = 0.3 soit 0.3 / 4.6 = 6.52 %
- B : 0.20 * 4 = 0.8 soit 10.8/4.6 = 7.4 %
- C : 0.70 * 5 =3.5 soit 3.5/4.6 =76 %
Si notre accélération consiste à mettre le double canal sur la mémoire ,ce qui réduira par 2 les temps d'accès à la mémoire, nous avons le CPI de la classe B qui passe de 4 à 2, le facteur d'amélioration du CPI est de 2.: La fraction F affectée est :7.4 % ou .074 c'est la classe B La fraction non affecté est 6.52%+76% = 92.6% ou .926 ceux sont la classe A et C La loi d'Amdahl nous donne : 1/((1-F) + F/S) soit 1/ (0.926+.074/2) = 1.04
Le double canal nous donne une amélioration de 5 % sur ce programme.
Un autre exemple d'application : si nous doublons le FSB d'un CPU pour un autre programme.
(Classe d'instruction,Temps d'exécution d'une instruction)(A,3),(B,4)(C,50)
La classe A représente des instructions de l'ALU qui n'accèdent pas à la mémoire. La classe B représente des instructions d'accès à la mémoire, lecture écriture. La classe C représente des instructions d'accès au disque dur.
Si nous avons pour chaque classe la fréquence d'utilisation des ces instructions dans un programme donné:
(Classe d'instructions,fréquence d'utilisation) (A,10%),(B,20%),(C,70%)
Ceci est un exemple de programme d'accès à une base de données :
Chaque classe représente un % du temps d'exécution total de ce programme : Fréquence d'utilisation * CPI / somme (des fréquences de chaque classe * CPI de chaque classe) 0.3 + 0.8 + 35 = 36.1 le temps du programme.
Classe d'instruction
- A : 0.10 * 3 = 0.3 soit 0.3 / 36.1 = 0.83 %
- B : 0.20 * 4 = 0.8 soit 0.8/36.1 = 2.2 %
- C : 0.70 * 50 =35 soit 3.5/36.1 =96 %
En doublant le FSB la fraction de programme impactée est 0.0083+0.022 =0.0303, le facteur S, d'amélioration est de 2. La fraction non impactée est 0.9697. La loi d'Amdahl indique que l'amélioration est 1/(0.967+0.0303/2)=1.018
Pour ce programme d'accès à des base de données, doubler le FSB améliore les performance de 1%. C'est normal, les accès disque représente 096 % du temps d'exécution et il ne sont pas améliorés.
Si nous divisons par 2 la durée des accès au disque avec un RAID 0, disque rapide et grand cache par exemple nous avons un facteur S d'amélioration de 2. La fraction impactée est 0.9697, la fraction non impactée est 0.0083+0.022 =0.0303 La loi d'Amdahl indique que l'amélioration est 1/(0.967/2+0.0303)=1.946
Pour ce programme d'accès à des base de données, diviser la durée des accès au disque par 2 améliore les performance de 94%.
En conclusion, le choix de l'optimisation dépend de ce que l'on veut améliorer. L'overclocking est bien adaptée au programmes gourmands en calculs comme les jeux. Mesurer le surfréquençage du C.P.U Mesurer le surfréquençage du C.P.U. avec SuperPi de l'université de Tokyo (voir Super PI).
Les deux points cités par le professeur Yasumasa Kanada, la puissance de calcul et la taille de la mémoire sont souvent cruciaux pour le surfréquençage. Le surcadençage du CPU et la diminution des temps de latences sont des axes exploités. A ce jour, un ordinateur de bureau dans le meilleur des cas met de 30 à 33 secondes sur le calcul de Pi à 1 M de décimales.
Un CPU overclocké peut descendre en dessous de 10 secondes !
Voici un autre type d'évaluation des performances des ordinateurs :
L'Université de Cambridge utilise d'autres types de mesure mais qui ressemblent à Superpi. http://www.hpcf.cam.ac.uk/history.html La mesure globale de la performance d'un Pc surcadencé avec 3DMark 2005 de la société Futuremark
Devant les nombreux paramètres intervenant dans la mesure d'un Pc avant et après le surfréquençage, il existe des produits permettant de mesurer les éventuelles améliorations d'une optimisation, 3dmark en fait partie. Il offre une vision synthétique sur les performances graphiques et CPU.
Liens externes
- (fr) Cooling-Masters.com
- (fr) Overclocking-pc.net
- (fr) XHReviews.com
- (fr) IxtremTek.com
- (fr) OverClocking-Masters.com
- (fr) JMax-Hardware.com
- (fr) Syndrome-OC.net
- (fr) OCTeam.fr
 Portail de l’informatique
Portail de l’informatique
Catégories : Culture informatique | Personnalisation du matériel informatique
Wikimedia Foundation. 2010.