- Maîtrise Statistique des Procédés
-
Maîtrise statistique des procédés
La maîtrise statistique des procédés (MSP) (Statistical Process Control ou SPC en anglais), est le contrôle statistiques des processus.
Au travers de représentations graphiques montrant les écarts (en + ou en -) à une valeur donnée de référence, il sert à anticiper sur les mesures à prendre pour améliorer n'importe quel processus de fabrication industrielle (automobile, métallurgie, ...).
C'est surtout au Japon après la Seconde Guerre mondiale que cette discipline s'est implantée grâce à William Edwards Deming, disciple de Walter A. Shewhart.
L'amélioration de la qualité des produits japonais avec l'utilisation systématique des cartes de contrôle a été telle, que les pays occidentaux ont développé à leur tour des outils pour le suivi de la qualité.
Cette discipline utilise un certain nombre de techniques telles le contrôle de réception, les plans d'expérience, les techniques de régression, les diagrammes de Pareto (Loi de Pareto), la capabilité.... et bien sûr, les cartes de contrôle.
Le contrôle en cours de production a pour but d'obtenir une production stable avec un minimum de produits non conformes aux spécifications. Le contrôle de la qualité est 'dynamique' : il ne s'intéresse pas au résultat isolé et instantané, mais au suivi dans le temps : il ne suffit pas qu'une pièce soit dans les limites des spécifications, il faut aussi surveiller la répartition chronologique des pièces à l'intérieur des intervalles de tolérances. La MSP ou SPC a pour objet une qualité accrue par l'utilisation d'outils statistiques visant à une production centrée et la moins dispersée possible.
Sommaire
- 1 Analyse graphique des données
- 2 Notions de statistiques appliquées au contrôle qualité
- 3 Normalité d'une distribution
- 4 Références
- 5 Voir aussi
Analyse graphique des données
La première phase, après la collecte des données est la visualisation de leur distribution. Différents outils graphiques proposés par les logiciels de contrôle statistique peuvent être utilisés pour les représentations graphiques de données statistiques
Nuage de points (ou nuée chronologique)
Le nuage de points permet de visualiser les données dans le temps par un numéro chronologique d'échantillon, une date, etc.
Exemple 1 : une entreprise industrielle fabrique des clés métalliques et note les longueurs moyenne des pièces obtenues sur un échantillon de 35 articles. Le tableau ci-dessous résume les longueurs moyennes en mm par numéro d'échantillon chronologique. Le nuage de points correspondant est le suivant:
N° P (mm) N° P(mm) N° P(mm) N° P (mm) N° P (mm) 1 139 8 137 15 130 22 131 29 128 2 139 9 124 16 137 23 135 30 134 3 141 10 128 17 125 24 128 31 127 4 134 11 136 18 139 25 127 32 133 5 127 12 134 19 132 26 136 33 131 6 131 13 133 20 128 27 133 34 131 7 132 14 133 21 137 28 141 35 139 Histogramme
Article détaillé : Histogramme.Un histogramme est un diagramme à rectangles (ou barres) dont les surfaces sont proportionnelles aux fréquences. Son tracé correct permet de réaliser le test de normalité loi de chi-2 . Il correspond à l'exemple 1. Cet histogramme a donné lieu aux résultats statistiques suivants :
statistique valeur nombre de valeurs 35 minimum 124 maximum 141 étendue 17 moyenne 132.676 variance 20.771 écart type 4.558 erreur standard 0.782 dissymétrie skewness 0.047 aplatissement kurtosis -0,831 Total des observations 4511.000 coefficient de variation 0.034 médiane 133 Boîte à moustaches
Le principe de la boîte à moustaches est de trier les données et de les répartir en quatre parties égales. À gauche du premier quartile se situent un quart des données, la moitié des données sont à gauche du second quartile (ou médiane), tandis que les trois quarts des données sont à gauche du troisième quartile.
Dans notre exemple, le premier quartile, sur le côté gauche de la boîte est proche de 128 mm. Le côté droit de la boîte montre le troisième quartile (137 mm). Ceci signifie que la moitié des clés sont comprises entre 128 et 137 mm. La médiane (ligne verticale dans la boîte) est d'environ 133 mm. On peut observer la bonne symétrie des données confirmée par l'histogramme.
Graphique tiges et feuilles

Le graphique 'tige-et-feuille ' (stem and leaf) est basé sur les valeurs numériques ordonnées des données de l'exemple 1 et ressemble à son histogramme. Il est très proche de la boîte à moustaches.
Les valeurs 124 , 125 seront représentées par la tige 12 et les feuilles 4 et 5. La valeur 127 retrouvée 3 fois par la tige 12 et les feuilles 777. Idem pour la valeur 128 retrouvée 4 fois 12 8888. Les autres tiges sont 13 et 14. Les tiges et les feuilles forment un graphique dont la longueur de chaque ligne est identique à la barre correspondante d'un histogramme horizontal. Dans ce graphique 'tige et feuille', les 2 H du graphe sont les premiers (128) et troisième (136) quartiles et le M la médiane (133). On retrouve ici la répartition symétrique des données!.
Notions de statistiques appliquées au contrôle qualité
Les méthodes et outils MSP font appel aux statistiques et plus précisément à la statistique mathématique.
Distribution de variables aléatoires discrètes
Généralités
Une population est un ensemble d'individus (pièce mécanique, échantillon de sable, boîtes..) sur lequel on suivra un ou plusieurs caractères (couleur, température, dimension, concentration, pH, etc.) Ce caractère peut être qualitatif (aspect, bon ou défectueux) ou quantitatif (taille, poids, nombre de défauts.) Dans ce dernier cas, les valeurs prises par le caractère constitueront une distribution discontinue ou continue. En pratique, les observations seront effectuées sur une partie de la population (échantillon statistique) prélevée au hasard.
Distribution binomiale
La loi binomiale est utilisée lors d'un tirage "non exhaustif" (avec remise). Elle peut être utilisée lorsque le rapport de la taille de l'échantillon (n) sur celle du lot (N) est telle que n / N
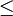 0,1. C'est le cas où les pièces prélevées pour l'échantillon ne sont pas remises dans le lot.
0,1. C'est le cas où les pièces prélevées pour l'échantillon ne sont pas remises dans le lot.La probabilité pour qu'il y ait k pièces défectueuses dans n tirages non exhaustifs (indépendants) est :
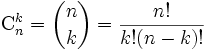
Exemple : Il s'agit d'évaluer les probabilités (P) d'observer X = 0,1,2,3,4,5 pièces défectueuses dans un échantillon de taille n =5 avec p =0,10 et q =0,90. La pièce est classée défectueuse si le diamètre est trop petit ou trop grand. La machine outil fournit 10% de pièces défectueuses dans un échantillon de taille 5.
X P 0 0,59049 1 0,32805 3 0,0729 4 0,00045 5 0 Cette loi est utilisée très souvent dans le contrôle de réception par attributs ou lors du contrôle de réception d'un lot. La variable binomiale suit une distribution discrête ne pouvant prendre que les valeurs entières 0,1,2,...,n.
Distribution hypergéométrique
Lorsqu'un contrôle implique la destruction complète des pièces ou éléments à contrôler, il est impossible d'effectuer un tirage exhaustif (sans remise). La loi hypergéométrique est utilisée à la place de la loi binomiale et sa représentation graphique est proche de cette dernière. La loi hypergéométrique a pour expression :
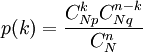
(q = 1 -p)
N: taille du lot.
n: taille de l'échantillon (n < N).
p: % de défectueux dans le lot initial.
C: nombre total de défectueux dans le lot.k : nombre de produits défectueux possibles dans l'échantillon de taille n.Distribution de Poisson
Lorsque n est grand et p faible, la loi de Poisson constitue une approximation de la loi binomiale. La probabilité d'avoir k pièces défectueuses dans un échantillon n donné est :
Une application courante de la loi de Poisson est la prédiction du nombre d'événements susceptibles de se produire sur une période de temps déterminée, par exemple, le nombre de voitures qui se présentent à un poste de péage en l'espace d'une minute. La loi de Poisson est une approximation de la loi binomiale si n > 40 et p < 0,1.
Distributions de variables aléatoires continues
Distribution normale
L'analyse des variables intervenant dans la production d'une machine (diamètre des pièces produites, poids ...) montre que si le réglage est constant, la répartition suit une courbe 'en cloche' dont les deux caractéristiques importantes sont la moyenne et la dispersion. La loi normale est très utilisée en contrôle statistique, surtout sous sa forme centrée réduite. wikisource : Table de la fonction de répartition de la loi normale centrée réduite. Dans la pratique MSP, une notion comme l'intervalle de confiance, est basée sur les probabilités de la loi normale. Par exemple, 68,3% de la surface sous la courbe d'une distribution normale signifie que 2/3 des observations se trouveront dans l'intervalle : [μ − σ; − μ + σ]. De même on estime à 95,4% la probabilité pour qu'une observation (dispersion = 6 fois l'écart type) se trouve dans l'intervalle: [μ − 2σ; − μ + 2σ]. L'intervalle [μ − 3σ; − μ + 3σ], contient 99.7 % des données. La loi normale est définie par ses deux premiers moments (m et σ). Son coefficient d'asymétrie est nul et son coefficient d'aplatissement égal à 3.
Ce qu'il faut retenir pour le contrôle de qualité est que la distribution normale est symétrique autour de la moyenne [μ], qui est aussi la médiane et s'étale d'autant plus autour de [μ] que l'écart type [σ] est plus grand. Le réglage de la machine est positionné sur la moyenne des pièces
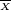 . Si la production est stabilisée, la répartition des caractéristiques d'une pièce sur une machine, suit une loi normale en raison du théorème central limite : tout système, soumis à de nombreux facteurs indépendants suit la loi de Gauss et dans ce cas, moyenne, médiane et mode sont égaux. Si n est le nombre de valeurs, l'écart type de la population est :
. Si la production est stabilisée, la répartition des caractéristiques d'une pièce sur une machine, suit une loi normale en raison du théorème central limite : tout système, soumis à de nombreux facteurs indépendants suit la loi de Gauss et dans ce cas, moyenne, médiane et mode sont égaux. Si n est le nombre de valeurs, l'écart type de la population est :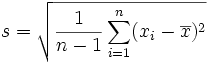 .
.
Distribution de Student
Cette distribution, encore appelée loi de Student ou loi t est basée sur la différence entre l'écart type de la population (σ) et celui de l'échantillon (s). Cette différence est d'autant plus grande que l'échantillon est petit si bien que la distribution n'est plus normale lorsqu'on utilise l'écart type de l'échantillon (s) au lieu de l'écart type de la population (σ) .
Le rapport :
suit une distribution de Student. Le paramètre (degré de liberté) représente la précision de l'écart type et détermine la forme de la courbe qui est symétrique, comme la distribution normale. Lorsque le nombre de degrés de libertés augmente, s devient une estimation plus précise de σ.
Distribution du khi-deux
On utilise cette distribution pour comparer deux proportions. En contrôle de réception, ce test, basé sur les probablilités, sert à mettre en évidence si le pourcentage de défectueux entre deux fournisseurs a ou non une signification statistique ou si elle est due au hasard. Comme la distribution de Student, le paramètre 'degré de liberté' donne une distribution de forme différente.
Distribution de Fisher
La distribution de Fisher (F) ou test de Fisher est utilisée en régression et analyse de la variance. F utilise 2 degrés de liberté, un au numérateur (m), l'autre au dénominateur (n).On la note F(m,n)
Distribution de Weibull
La loi de Weibull généralise la loi exponentielle. Elle modélise des durées de vie.
Statistique descriptive
Le contrôle de la qualité utilise un certain nombre de termes techniques : échantillon, population, caractère....explicités dans la statistique descriptive. De même, les critères de position (moyenne, mode, médiane) et de dispersion (étendue, écart-type) sont nécessaires à la compréhension de l'histogramme.
La moyenne arithmétique est le paramètre de position le plus représentatif, car le plus sensible aux fluctuations. Par contre, la médiane et le mode sont plus simples à déterminer, ne nécessitant aucun calcul.
L'estimateur du paramètre de dispersion le plus sensible est l'écart-type basé sur la variation de l'ensemble des valeurs par rapport à la moyenne.
L'étendue, lorsque la taille de l'échantillon est faible (n < 7), est un bon estimateur de la dispersion. Il est utilisé fréquemment dans les cartes de contrôles de mesures.
Estimation par intervalle de confiance
En pratique, on ne peut se fier à l'estimation de paramètres tels que la moyenne ou l'écart-type d'une façon ponctuelle (voir critères de dispersion et erreur (métrologie) sur les mesures). On cherche à trouver un intervalle dans lequel les paramètres inconnus et estimés ont une chance de se situer. C'est le principe de l'estimation par intervalle de confiance.
Intervalle de confiance sur la moyenne
Intervalle de confiance sur la variance
Normalité d'une distribution
Généralités
Les tests qui suivent permettent de s'assurer de la normalité des résultats obtenus.
Droite de Henry
Sur un simple examen de l'histogramme, il n'est pas évident de se prononcer sur la 'normalité' des variables. Il est pratique de comparer le graphique obtenu avec les données théoriques correspondantes basées sur une loi théorique standardisée et de représenter ces données sur une droite à l'aide d'un changement d'échelle. La droite de Henry permet de réaliser cette transformation. On constate que la distribution de l'exemple 1 est quasi-normale.
La droite de Henry coupe l'axe des x au point d'abscisse m et sa pente est égale à 1/σ, ce qui permet une estimation de l'écart-type de la distribution.
Moyenne de moyennes de données
Si l'on suppose que la population dont on a extrait l'échantillon est normale et a pour paramètres théoriques X = 133 mm (moyenne) et σ = 5 mm, alors on peut tracer l'histogramme de loi normale centrée réduite correspondante sur une simulation de 1000 pièces tirées au hasard. La moyenne théorique est de 133 mm, l'écart type de 5 mm et l'étendue de 34 mm. Puisque notre échantillon de 32 données suit approximativement une loi normale, on peut se poser la question de savoir si la moyenne théorique de la population serait plus précise si on multipliait le nombre des séries d'observations. Simulons par exemple 9 prélévements successifs de 1000 pièces de moyenne théorique 133 mm et d'écart type 5 mm. La moyenne théorique obtenue est de 120mm, l'écart type de 4,8 mm et l'étendue de 32 mm. La distribution de la 'moyenne des moyennes' semble normale. L'histogramme est centré sur la moyenne théorique (120), mais la distribution de la moyenne est plus ressérée que dans l'histogramme ci-dessus. La moyenne de l'échantillon donne donc une moyenne plus précise de la moyenne théorique qu'une seule série d'observations X. Soit Mm, la moyenne des moyennes.
On démontre que pour n séries d'observations :
- Moyenne Mm = moyenne (X )d'une série d'observations.
- Écart type de Mm =
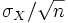 .
. - Variance de Mm = variance (X) / n.
Théorème de la limite centrale
En contrôle qualité, la plupart des distributions de données d'échantillons suivent une loi normale. Si toutefois les données ne semblent pas « normales », le théorème de la limite centrale permet d'affirmer que la moyenne d'une variable indépendante distribuée de façon quelconque devient une variable normale quand le nombre d'observations est assez grand.
La moyenne arithmétique
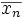 de n valeurs suivant une même loi de probabilité tend vers son espérance mathématique E(X). Plus n est grand, plus la loi se rapproche d'une distribution normale. Son écart type est :
de n valeurs suivant une même loi de probabilité tend vers son espérance mathématique E(X). Plus n est grand, plus la loi se rapproche d'une distribution normale. Son écart type est :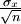
Donc, si n est > 5, par exemple, la distribution des moyennes
des différents échantillons successifs tirés de cette même population tendra vers une loi normale de même moyenne m et d'écart-type , même si la variable aléatoire x ne suit pas une loi normale. Cette propriété est utilisée dans les cartes de contrôle aux mesures.Test du khi-deux
Article détaillé : Test du χ².Cartes de contrôle
La carte de contrôle
La carte de contrôle est le principal outil de la MSP. On se propose de tracer les cartes de contrôle à la moyenne et à l'étendue de l'exemple.
N° X1 X2 X3 X4 X5 X R 1 130 136 135 137 138 135,2 5,2 2 134 133 135 135 137 134,8 5,2 3 137 136 135 135 133 135,2 5,2 4 135 135 138 137 137 136,4 5,2 5 135 134 135 138 137 136,4 5,2 6 135 134 135 135 138 135,4 5 7 138 135 138 135 138 136,4 4,9 8 134 140 135 132 135 135,2 4,9 9 135 133 133 135 135 134,2 4,9 10 134 134 135 138 137 135,6 5,1 11 132 139 135 138 135 135,8 5 12 134 140 135 135 137 136,2 5,1 13 131 139 130 135 135 134 5 14 134 135 139 138 135 136,2 4,9 15 136 135 139 131 135 135,2 4,9 16 133 133 135 132 131 132,8 5,1 17 135 131 131 135 135 133,4 4,9 18 135 135 138 131 131 134 5,3 19 131 139 133 135 132 134 4,9 20 131 138 136 135 138 135,6 5,1 Pièce : clé métallique.
Caractéristique : Longueur.
Unité de mesure : mm.
Fréquence de contrôle : toutes les 2 heures.
En appliquant les coefficients de calcul des limites pour 5 prélèvements par échantillon, on calcule pour chaque ligne, la moyenne X et l'étendue R par échantillon, puis la moyenne des moyennes et l'étendue moyenne sur l'ensemble des échantillons. (20 lignes)
A2 = 0,577
D4 = 2,115
D3 = 0
Pour la carte à la moyenne (en haut), les limites du contrôle sont :
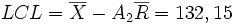
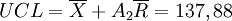
Pour la carte à l'étendue (en bas) :
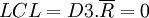
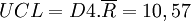
Le procédé de fabrication est sous contrôle.
Utilisation des différentes cartes
Optimisation de la qualité
Analyse de la variance
Ajustements
Analyse des causes de non conformité
Références
- Maurice Pillet, Appliquer la maîtrise statistique des processus. MSP/SPC, Eyrolles, 6e édition, 2005
- Gérald Baillargeon (1980). 'Introduction aux méthodes statistiques en contrôle de la qualité' . Les éditions SMG. (ISBN 2-89094-008-X)
- Elbekkaye Ziane (1993). Maîtrise de la qualité totale. Hermès. (ISBN 2-86601-362-X)
- Kenneth N. Berk et Jeffrey W.Steagall. Analyse statistiques des données avec Student Systat . International Thomson Publishing France. (ISBN 2-84180-003-2)
Voir aussi
- Carte de contrôle
- Capabilité machine
- Capabilité procédé
Catégorie : Management de la qualité

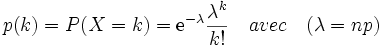
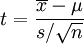
Wikimedia Foundation. 2010.